
微博存储问题凸显
微博Feed由关注人的微博聚合而成,存储每个人发的微博至关重要。在如今社交媒体火爆的当下,微博用户众多、数据海量,怎么设计出高效的存储架构成了当务之急。要是存储架构不给力,不仅会影响用户体验,还可能让微博平台运营成本大幅增加。
这就好比建房子,地基打得不好,房子迟早出问题。微博存储架构就是“地基”,得把它设计好才能支撑起整个微博业务的稳定运行。
持久化存储与数据库选择
从微博业务实际情况来看,用户微博需要永久保存,也就是要持久化存储。而且微博数据结构固定,所以关系型数据库是优先选择。像 MySQL 就比较合适,很多大型系统都用它。
有数据显示,很多知名社交平台都采用关系型数据库存储数据。用 MySQL 存储微博数据,能确保数据的完整性和一致性,方便后续的查询和管理。这对于依赖数据的微博业务来说非常关键。
单数据库瓶颈问题
不过,单台 MySQL 读能力有极限,不到一万 QPS,可微博的数据请求量达到几百万 QPS。要是单纯用 MySQL,那得需要上千台服务器,成本高得惊人。
举个例子,有一个小型社交网站,一开始只用单一数据库应对数据请求,结果随着用户增多,数据请求量变大,服务器响应慢,用户体验差,最后不得不投入大量资金升级硬件和优化架构。微博如果也这么干,成本压力太大。
引入缓存机制

为了解决成本问题,可以在 MySQL 前面加一层缓存,比如用 Memcached。把最近一周内的微博存储在缓存里,全量微博数据存到 MySQL。
假设用户访问一周内微博概率是 99%,这样大部分请求就会去缓存里找数据,对数据库的请求量就从几百万 QPS 降到几万 QPS。缓存读写能力达几十万 QPS,所需机器数比单用数据库少多了。就像商店把热门商品放在显眼地方,方便顾客快速找到,提高效率。
推模式和拉模式选择
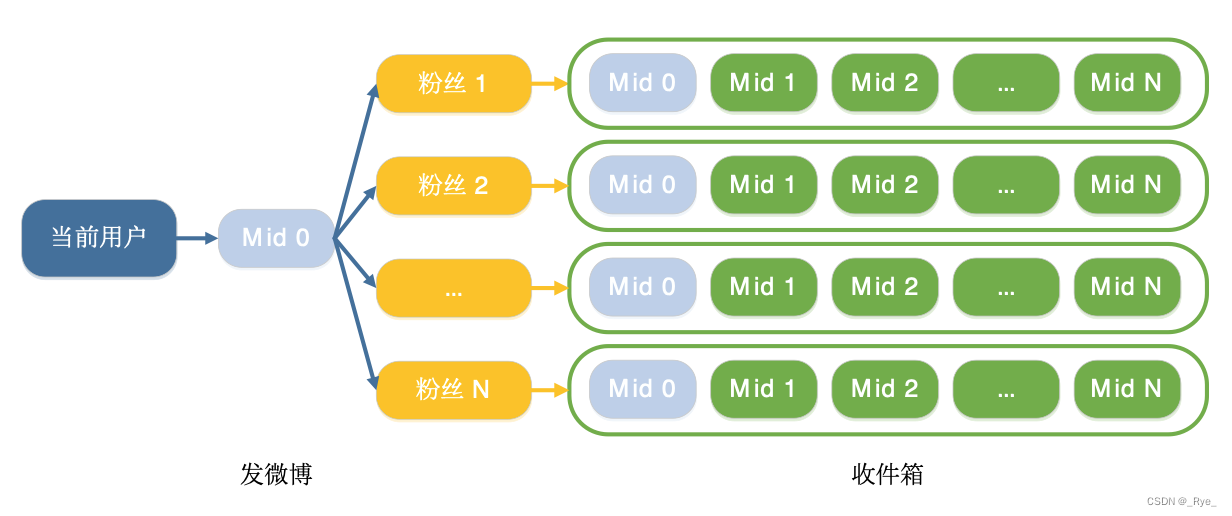
微博是公开平台,很多用户有大量粉丝。如果采用推模式,存储成本和数据更新成本特别高,需要大量缓存、数据库和队列机更新。
但每个用户微博只存在自己发件箱列表里,拉模式存储成本小得多。要是有数据修改,只改自己发件箱就行。比如大明星的微博,如果用推模式推送,得推送给大量粉丝,资源消耗极大;用拉模式,粉丝主动去拉就好。对于粉丝量大的用户用拉模式,一般用户用推模式问题不大。
提高拉取效率方法
对于关注人数上千的用户,拉取 Feed 效率低。可以采用分而治之的思想,把关注人分组,并行拉取。
这就类似于 MapReduce 的思路,把一次性聚合计算操作分解成多次操作,最后汇总结果。像处理大规模数据时,这种分治方法能大大提高效率。通过这种方式,能极大改善此类用户的拉取体验。
你觉得微博未来会采用更先进的数据库来进一步优化存储架构吗?如果觉得这篇文章有用,就点赞和分享给更多人!



