
你有没有遇到过这样的情况,想要拿到快手视频的播放地址,明明看到网页里有json串,可代码请求时却不见它的踪影?这就像一场捉迷藏,让人摸不着头脑,这背后到底隐藏着什么秘密?
网页查找初发现
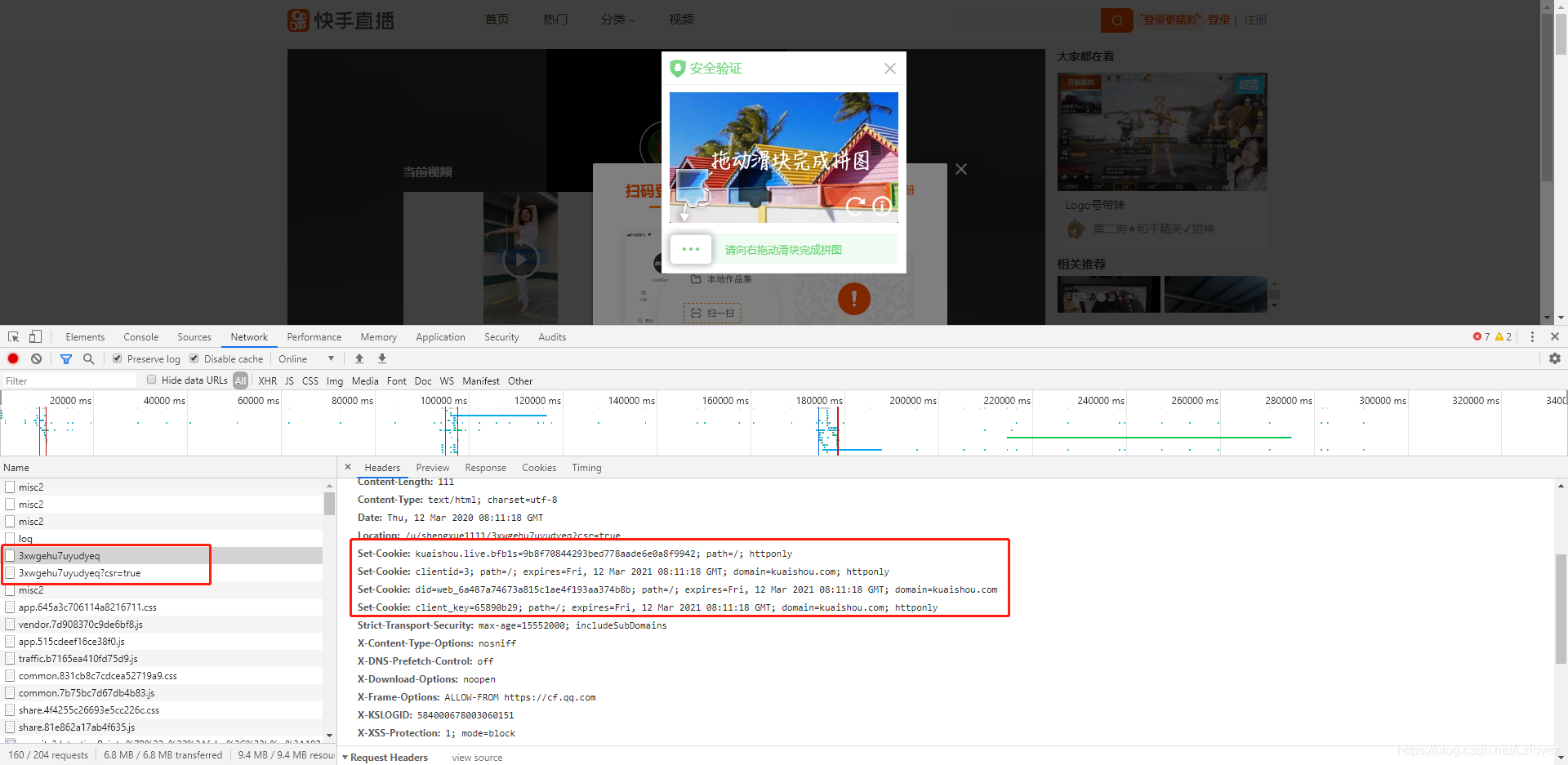
当我们在快手中找到视频播放地址时,首先会采用F12进行查看。在网页返回的最后我们能看到一个json串的存在。这个json串看起来像是找到播放地址的重要线索。但它的出现像是一个误导,因为在实际用代码请求的时候,这个东西就失踪了。这时候就像是进入了一个迷宫,初始以为的出口并不是真正的出口。
这时候我们就需要重新审视整个查找过程。也许我们最初的以为的这种查找方式太过于简单和直接。也许快手的播放地址获取有着自己复杂的规则,不能仅仅依靠看到的这个json串就以为可以顺利拿到播放地址。
地址栏变化的疑惑
我们发现地址栏发生了变化,例如变为了某个特定的网址。这一变化会让我们想知道到底是什么引起了这种变化。是快手的安全机制在起作用吗?还是网页本身的跳转逻辑导致的?
为了探究原因,我们开始进行一些尝试。就像是在黑暗中摸索,不放过任何一个可能的原因。而且这时候我们不能仅仅只看表面的现象,必须深入探究地址栏背后的网页跳转原理,或许才能找到解答当前疑惑的答案。
清除缓存寻找端倪
鉴于可能有跳转的猜测,我们清空了cookie和缓存文件,重新请求。这个过程像是把之前的干扰因素都清除掉,重新开始探索。这时候终于发现了一些端倪。有时候我们在解决问题时,就需要这种重新归零的决心。
经过清除缓存和cookie后重新请求,我们仿佛看到了迷宫中的一条新路径。虽然还没有完全找到播放地址,但起码看到了一丝希望,这一丝希望或许就能引导我们最终找到解决的办法。
首页跳转的真相
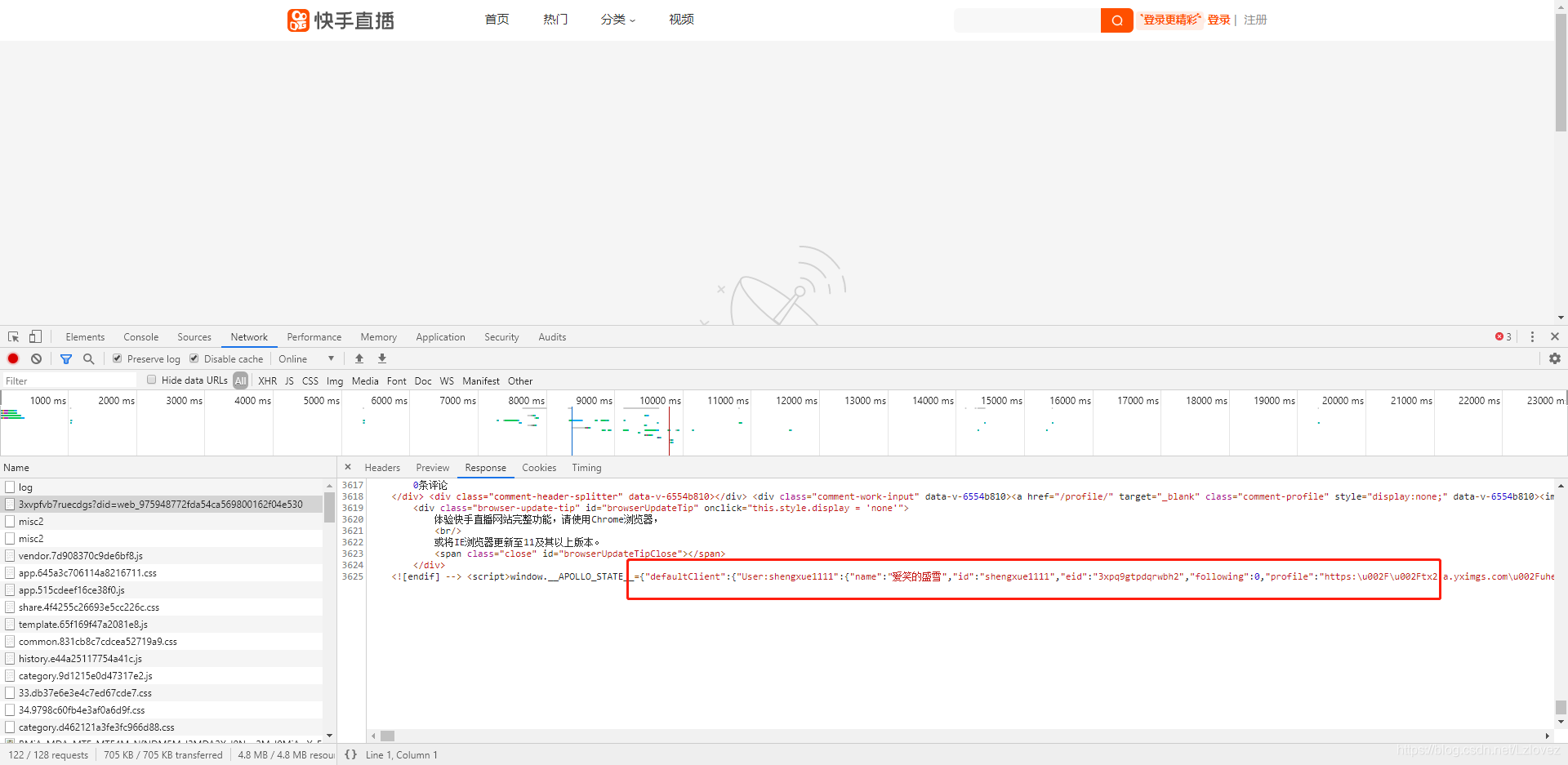
通过一番探究,我们发现其实是首页进行了跳转。并且在response里面有set - cookie的情况。这个真相的发现,像是揭开了神秘面纱的一角。原来我们之前那些疑惑都是和首页的跳转有关系的。
知道了这个真相后,我们就可以根据这个新的发现重新调整探索播放地址的策略。就像是在战场上重新制定作战计划一样。而且我们要把这个新发现放在整个探索的体系中,进一步思考如何获取播放地址。
代码操作的关键
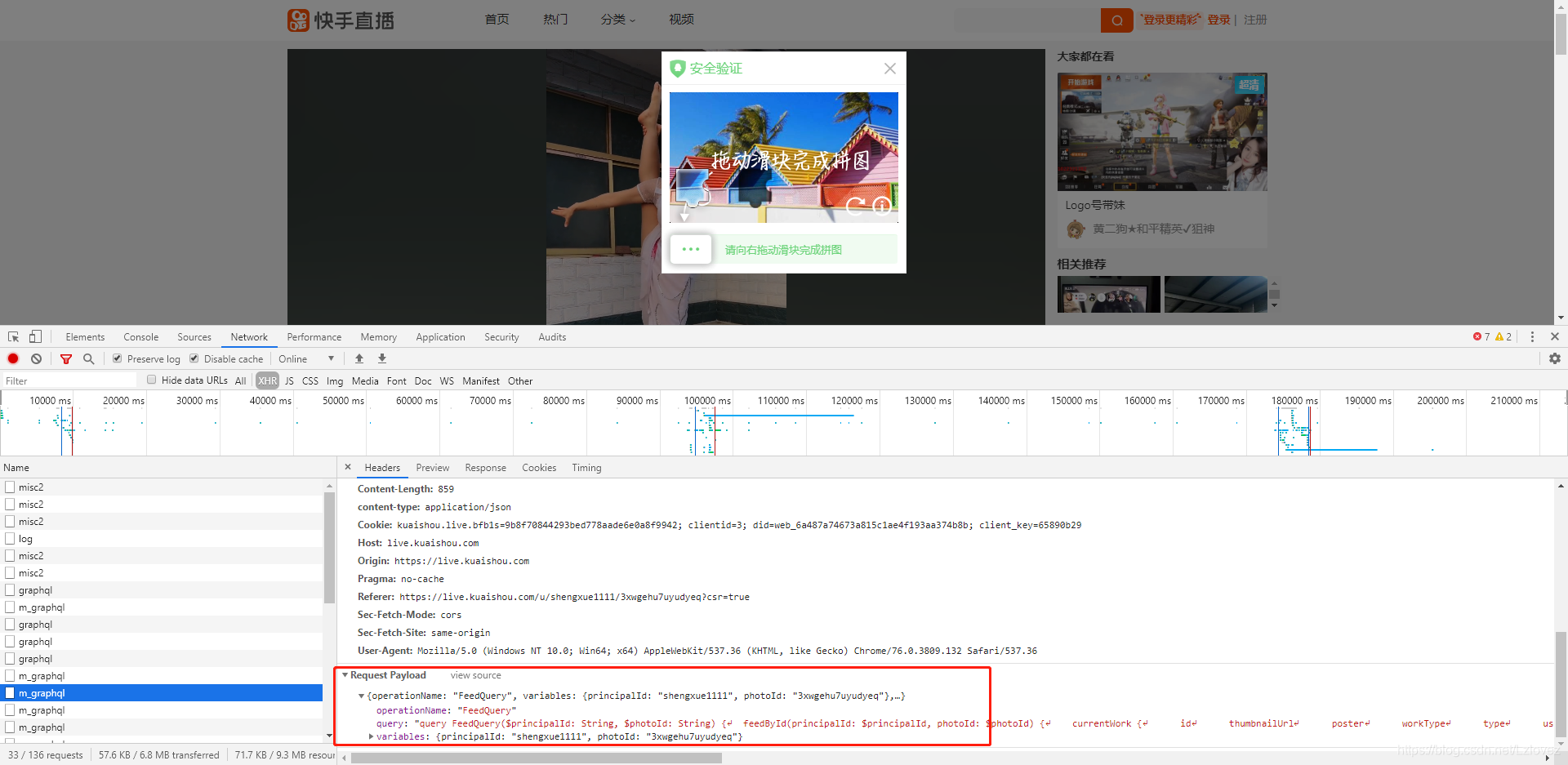
找到了一些线索后,就到了上代码的时候了。大致就是请求具体的链接,从响应里面获取cookie,再请求JSON数据。在这个过程中我们需要非常小心和精确。每一步代码的编写都像是在搭建一座桥梁,容不得一点差错。
以shengxue1111这个用户ID和3xwgehu7uyudyeq这个视频ID为例,它们是具体操作中的关键元素。这些参数正确输入和使用是成功获取播放地址的重要因素。就像数字密码一样,错一个都不行。
获取播放地址的总结
综合以上的探索之旅,我们从最开始看到的json串的迷惑,到发现地址栏变化、首页跳转,再到清除缓存后有了新发现,以及最后的代码操作。每一个步骤都不是那么简单容易的。整个过程是一个充满曲折的发现之旅。
这也体现出获取快手播放地址并不是从网页表面上看起来那么直观。它要求我们严谨、精细地对待每一个可能的影响因素。这也为后来想要获取类似视频播放地址的人们提供了一些经验和教训。
那么你在获取视频播放地址的时候有没有遇到过类似出人意料的情况?欢迎在评论区留言分享,也希望大家点赞和分享这篇文章。
# coding:utf-8
import pymysql
import requests
import re
import time
import json
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'Host': 'live.kuaishou.com',
'content-type': 'application/json',
}
url = data[1]
print(f"开始请求 {url}")
response = None
response = requests.get(url, headers=headers)
text = response.text
cookie = response.cookies.get_dict()
did = cookie['did']
if not did:
print(f"未获取到did {sid}")
return
time.sleep(3)
cookie_str = ''
for key in cookie:
cookie_str += key + ":" + cookie[key] + ";"
headers['cookie'] = cookie_str
headers['Referer'] = url + '?csr=true'
params = {
"operationName": "FeedQuery",
"query": "query FeedQuery($principalId: String, $photoId: String) {\n feedById(principalId: $principalId, photoId: $photoId) {\n currentWork {\n id\n thumbnailUrl\n poster\n workType\n type\n useVideoPlayer\n imgUrls\n imgSizes\n magicFace\n musicName\n caption\n location\n liked\n onlyFollowerCanComment\n relativeHeight\n timestamp\n width\n height\n counts {\n displayView\n displayLike\n displayComment\n __typename\n }\n user {\n id\n eid\n name\n avatar\n __typename\n }\n expTag\n playUrl\n __typename\n }\n status\n errMsg\n __typename\n }\n}\n",
"variables": {
"principalId": author_id,
"photoId": video_id
}
}
response = requests.post('https://live.kuaishou.com/m_graphql', headers=headers, json=params)
text = response.text
j = json.loads(text)
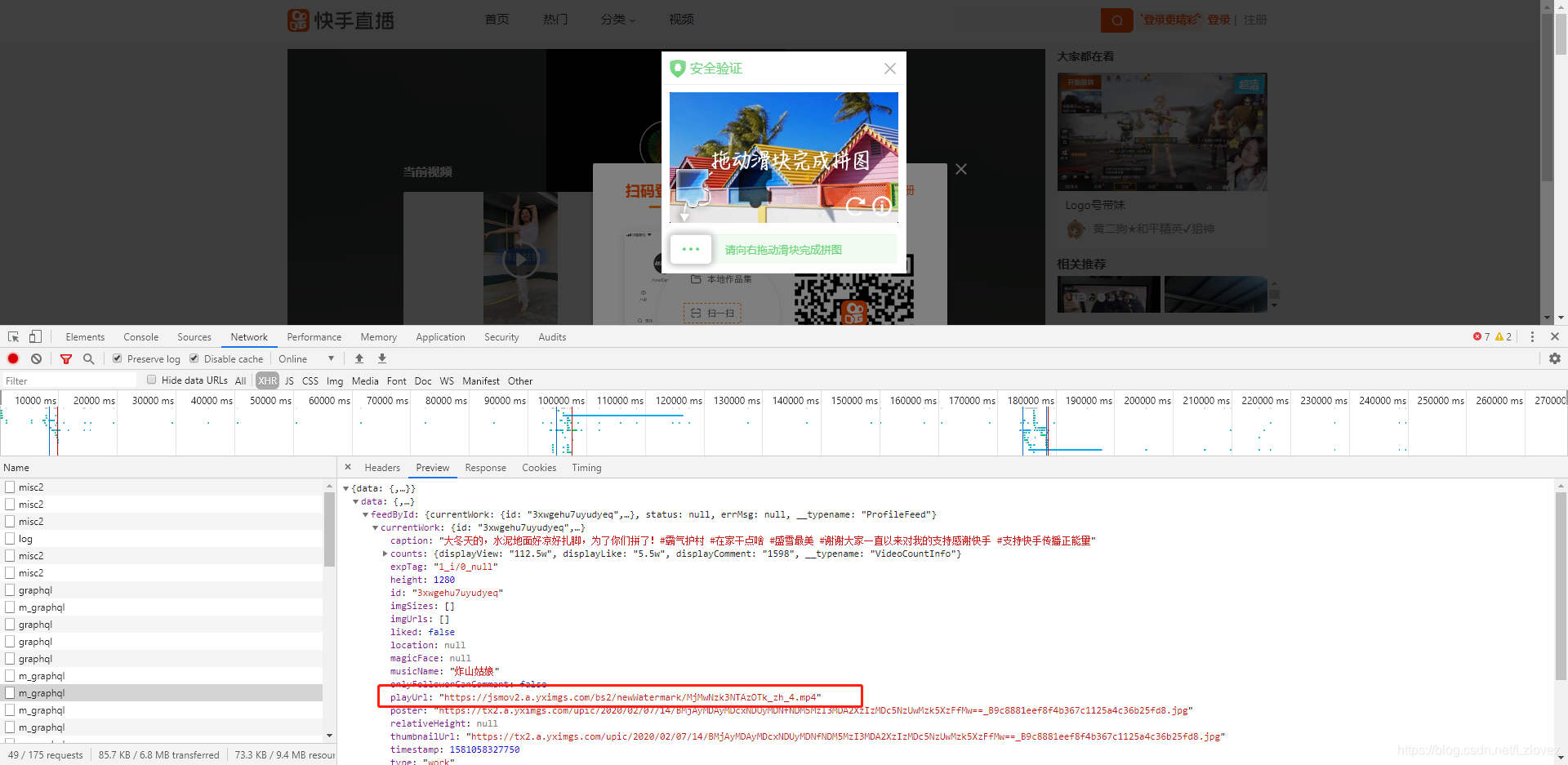
playUrl = None
try:
playUrl = j.get('data').get('feedById').get('currentWork').get('playUrl')
except Exception as e:
pass
if not playUrl:
print(f"没有找到地址 {sid},{url}")
return;
print(playUrl)







