

微博推荐引擎在微博的诸多推荐业务中处于枢纽地位,支撑着热门流、小视频后推荐等业务。然而它在快速迭代时可靠性问题突显,这不仅影响用户体验,也对微博的运营发展带来挑战,这无疑是一个值得关注的痛点。
微博推荐引擎的重要地位
微博推荐引擎关联到微博众多推荐业务。无论是热门流还是视频后推荐等业务,它都是核心驱动环节。它得结合特征、模型、物料等环节让业务顺利运行。就像微博这样的社交平台,大量用户每天在上面浏览,微博推荐引擎得时时刻刻运行准确,在南京的某微博深度用户,日常通过热门流获取信息,如果引擎出现问题,他可能错过很多热点资讯。也因为它的特殊地位,一旦出现问题,影响的将是众多使用者。
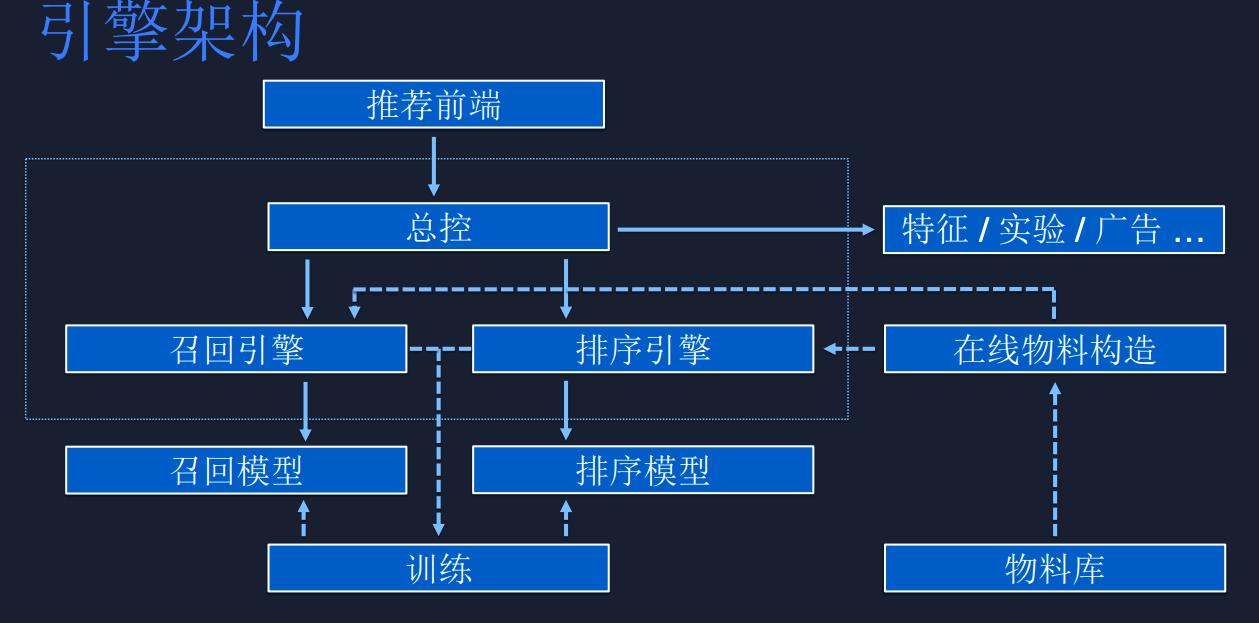
微博推荐引擎作为枢纽,出现问题会产生连锁反应。像国内有很多依赖推荐业务的小微博账号博主,他们靠热门流等推荐来增加曝光度。若推荐引擎不稳定,这些博主的流量、收益等都会受影响。
可靠性问题表现
稳定性与业务支持方面问题逐渐暴露。微博推荐引擎在快速迭代时,其稳定性难以保障。例如,在北京的微博研发团队在测试中发现,其系统有时无法及时响应推荐请求。还有业务支持方面,它在面对一些特殊要求或者用户行为变化时,表现得有些力不从心。


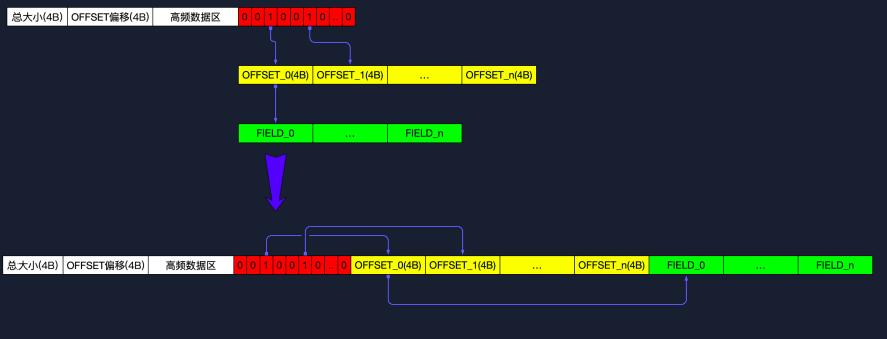
它还面临架构上的问题。其架构在设计上存在不合理之处。比如说排序引擎对物料的处理方式,一次要处理大量数据,且原物料携带特征多,这导致处理速度慢、内存性能差。在上海某机房测试时,发现这种数据处理方式严重拖慢整体运营效率,还限制了可处理的物料规模。
改造中的困难
改造微博推荐引擎艰难重重。必须梳理几十万行代码,这需要耗费大量精力。在改造期间,系统还不能下线,因为要持续迭代以维持业务运行。以广州微博技术部门为例,很难在保证日常业务的同时,抽出足够人力搞改造。
除内部因素外,外部也存在压力。公司对成本、机器利用率等有要求,这使得改造在资源受限的情况下进行。很多时候,外部的指标要求与内部技术提升相互牵制。
解决方案尝试
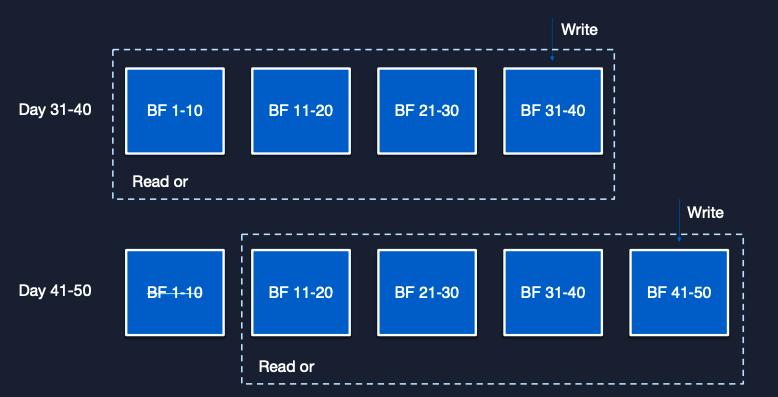
在解决问题的道路上,首先从运维工具入手。接入成熟运维工具后,组合自主开发的自动处置工具,优化上线脚本,实现基于QPS和超时率的缩扩容功能。比如在日常运营中,当流量高峰期,可自动扩容。在杭州的数据中心测试时,这一功能有效分担了流量压力。

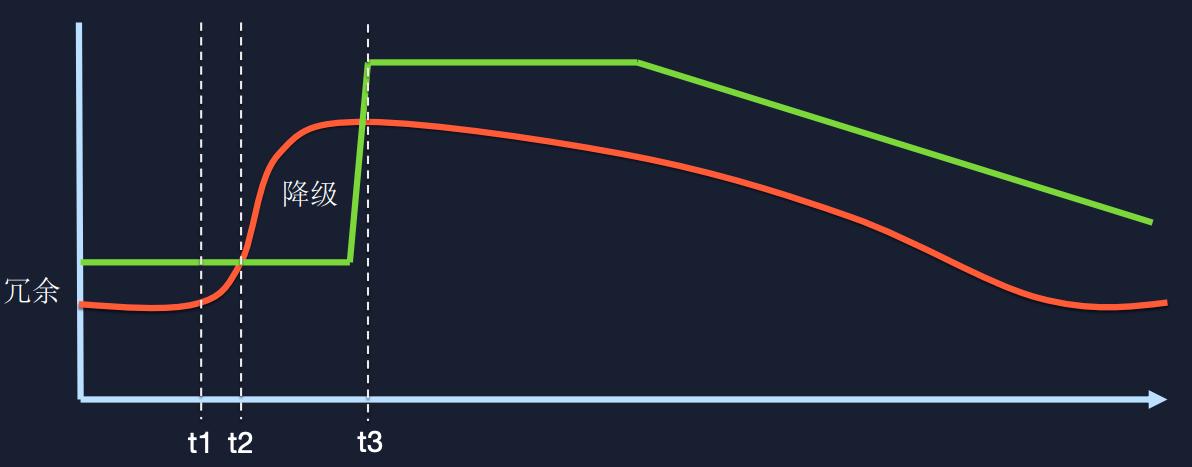
还建立了降级策略应对特殊情况。一方面,建立短期已读存储,当主资源不可用时能提供降级服务。另一方面,在扩容时可停止某些次要功能来保障主要功能。像微博运营中有特殊节日流量爆发时,这些策略能保证微博推荐引擎基本运转。
结合公司情况处理问题
不同公司情况不同,处理方式也得因地制宜。若公司成本压力小,可适当提高冗余度。比如某微博分公司所在地区对互联网产业扶持力度大,成本投入有补贴模式,那这个地区可能就会选择调高冗余度。
还可根据历史流量数据做针对性处理。比如分析过往的流量高峰、低谷时期数据,在流量高峰可能到来之际提前做好准备,如增加服务器等资源或者优化某些功能模块。
改造成果显著
微博推荐改造项目历时三个月成果显著。正常请求的处理比例大幅提升,从不到99%达到99.9%以上。在人力物力资源不变的情况下,服务耗时降低了25%。不额外增加资源就能单机处理500万 - 1000万物料,启动速度还提升到原来的4倍。这一系列成果表明之前的改造方向正确且有效。
你是否觉得微博推荐引擎的可靠性还有其他可改进的地方?希望大家点赞分享并在评论区讨论。



