
如今部分客户在广告投放上还较传统,缺乏创意,效果欠佳,而微博商业数据挖掘体系以用户画像为核心建设,这里面有着怎样的奥秘?
传统广告投放痛点
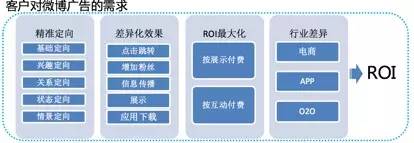
许多客户仍遵循传统联盟广告模式,投放方式单一,多是按部就班地进行广告展示。在这种模式下,客户较少考虑创意生成,往往采用固定模板,导致广告缺乏吸引力。在市场竞争激烈的当下,比如在促销季,众多同质化广告出现,用户极易产生审美疲劳,最终广告效果很差,难以给企业带来实际收益。
这种单一的投放方式使得客户很难精准触达目标用户群体。以服装广告为例,若只是在固定平台、固定时段展示,可能无法吸引到有购买意愿的人群,浪费了大量的广告成本,而本应获得的流量和订单却难以实现。
微博数据挖掘核心
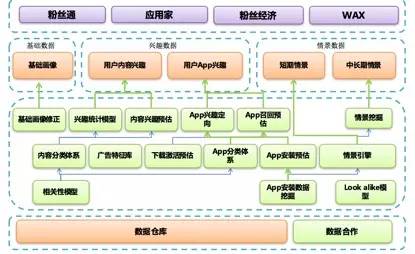
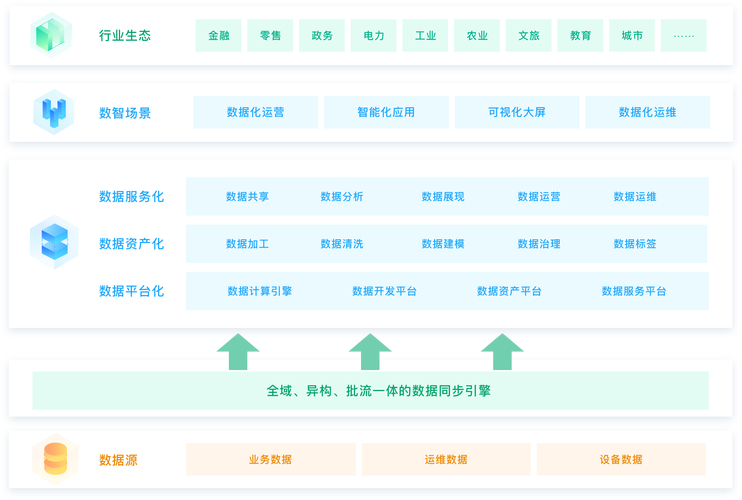
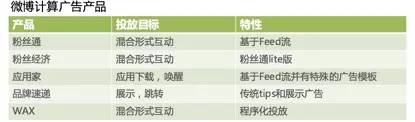
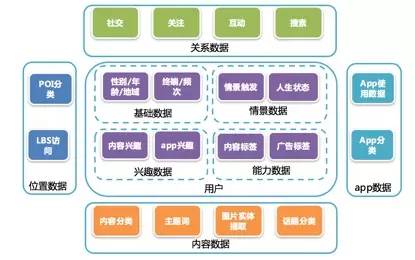
微博商业数据挖掘体系围绕流量细分展开,也就是以用户画像为核心建设。通过收集用户的各种行为数据,如关注、点赞、评论等,深度分析用户特征和兴趣点,构建起相对精准的用户画像。例如,通过对用户关注的话题和账号进行分类,可以了解用户的兴趣领域。
这种数据挖掘方式有助于广告投放的精准定位。借助用户画像,广告主能够知道哪些用户更有可能对自己的产品感兴趣,从而更有针对性地进行广告推送,提高广告的点击率和转化率,实现资源的优化利用。
不同数据挖掘级别
Ground Truth级有一个足够规模的数据集,可作为标注集和交叉验证的测试集,能运用监督学习算法做分类。这个级别的数据挖掘精度较高,像在进行大规模用户行为预测时,利用充足的数据能让预测结果更准确。
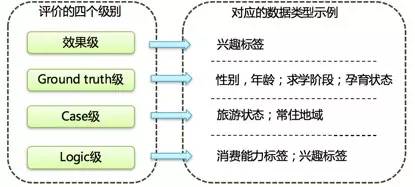
Case级则不具备有统计意义的标准数据集,无法获得标注数据,但能通过人工到微博用户页面判断分类结果是否准确。不过这种方式效率较低,只适用于小范围的验证和调整,比如对少量特殊用户群体的分类检查。
用户常住城市判定
挖掘用户常住城市主要依赖IBS信息及IP地址,其他特征对这个标签贡献有限。因为这两个信息相对稳定且能反映用户的地域位置,通过特定规则来进行判定。例如,长期稳定的IP地址能大致确定用户所在城市。
对规则分类的结果抽样后,人工去用户微博页面检验。这样可以保证城市标签的准确性,在广告投放中,能更精准地针对不同城市的用户进行推广,提高广告的地域针对性。
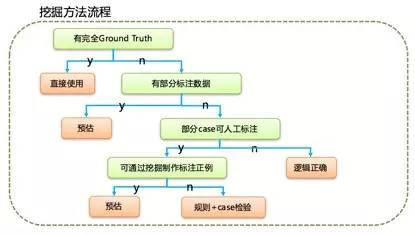
数据评价体系现状
除兴趣标签外,能直接用效果来评价的数据较少,业务层面假设过多,实践中仅作参考。在数据的实际应用中,由于缺乏直接有效的评价标准,很多数据的价值难以衡量。
在该评价体系下,数据工程师不对兴趣标签之外挖掘结果的广告效果负责。这是因为评价方向和业务重点决定了工程师的工作重点,对于一些非兴趣标签的数据挖掘,更多是作为辅助参考,难以直接参与效果优化。
兴趣标签挖掘方法
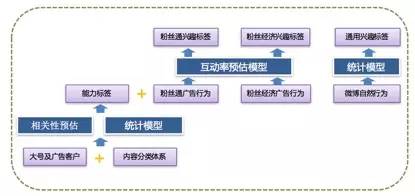
在不指定具体广告投放场景时,兴趣意味着用户对相关内容历史关注或互动率较高。通过统计每个用户对大号的关注关系,若高于平均值就视作感兴趣,能快速判断用户兴趣。
用机器学习模型(FM或LR)预估用户对广告目标行为的概率,高于阈值就认为有兴趣。在实际广告运营中,还会针对广告主做专属定向包,进一步细化用户兴趣,提高广告投放的精准度。
了解了这么多关于微博商业数据挖掘和广告投放的内容,你认为哪种兴趣标签挖掘方法在实际中更具效果?







