
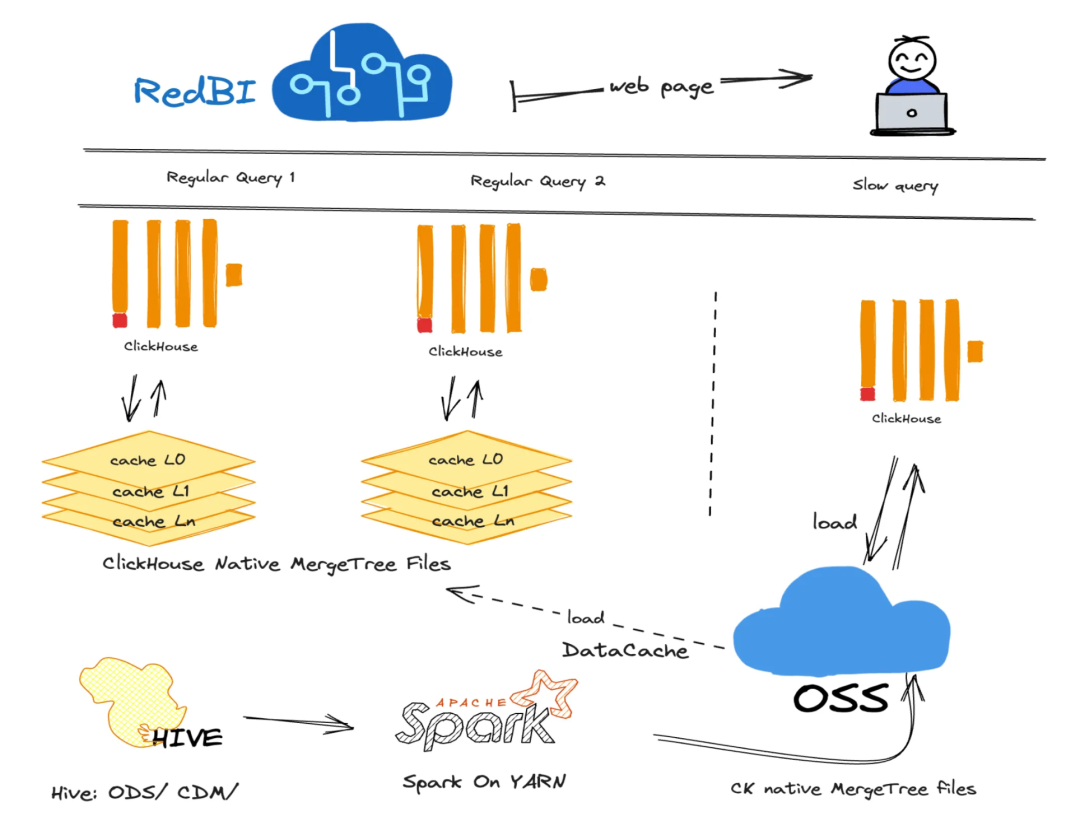
现状与痛点
随着业务发展,分析师使用习惯不断变化,最初制定的索引策略失效,数据集查询性能下降。现有架构缺乏灵活机制调整排序键与索引,维度表复用难,Join操作灵活性受限。而且数据访问方式单一,只能通过ClickHouse查询,很多时候难以满足不同分析需求,查询性能越来越差。
这种状况严重影响了分析师的工作效率,需要尽快找到解决办法,不然业务发展会受阻。
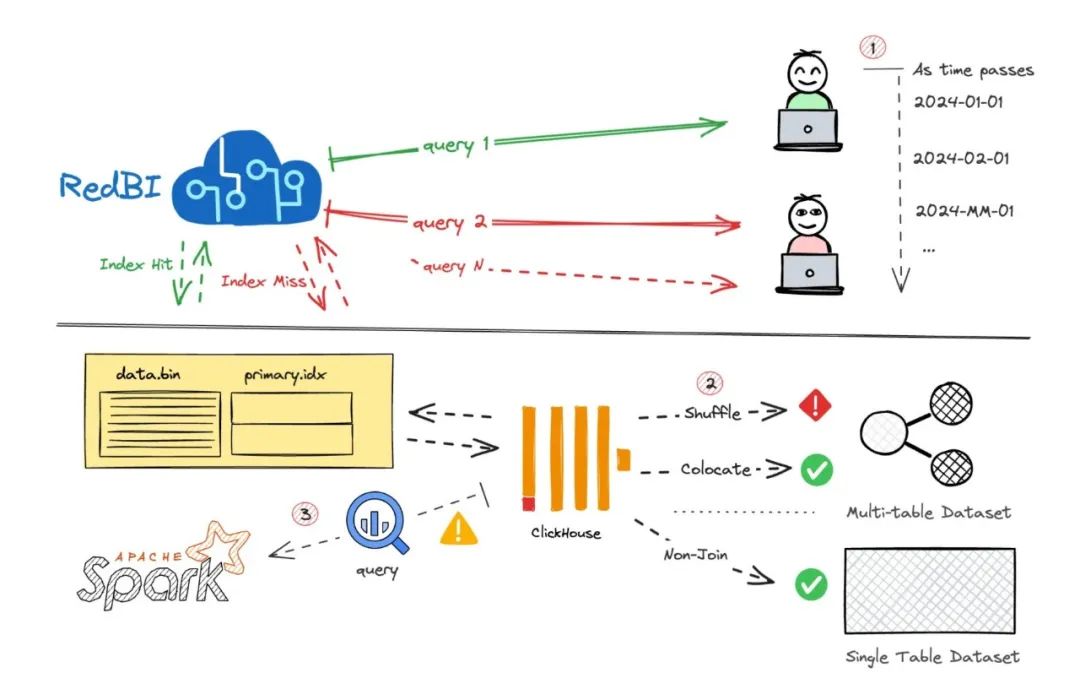
性能优化之数据缓存
为改善查询性能,将热点数据缓存至本地BE节点是个好办法。StarRocks DataCache将外部存储原始数据切块缓存到本地,能避免频繁远程拉取数据。减少了重复的数据拉取,既提升了查询稳定性与响应速度,也显著提高了查询和分析性能,节约了大量时间和资源。
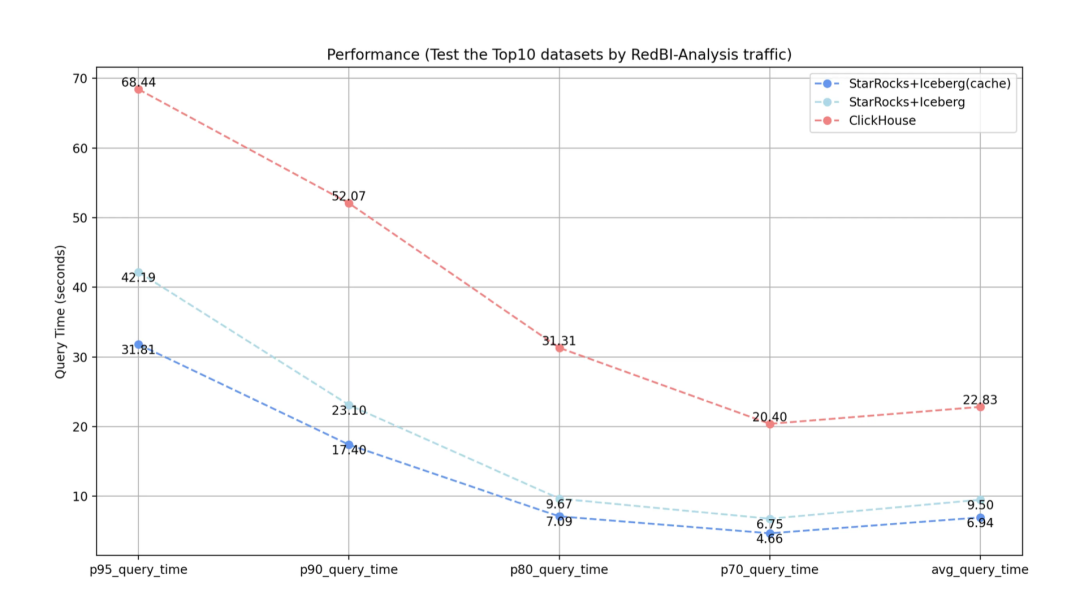
例如在某大型业务分析场景中,实施数据缓存后查询响应时间大幅缩短,提升了数据处理效率。
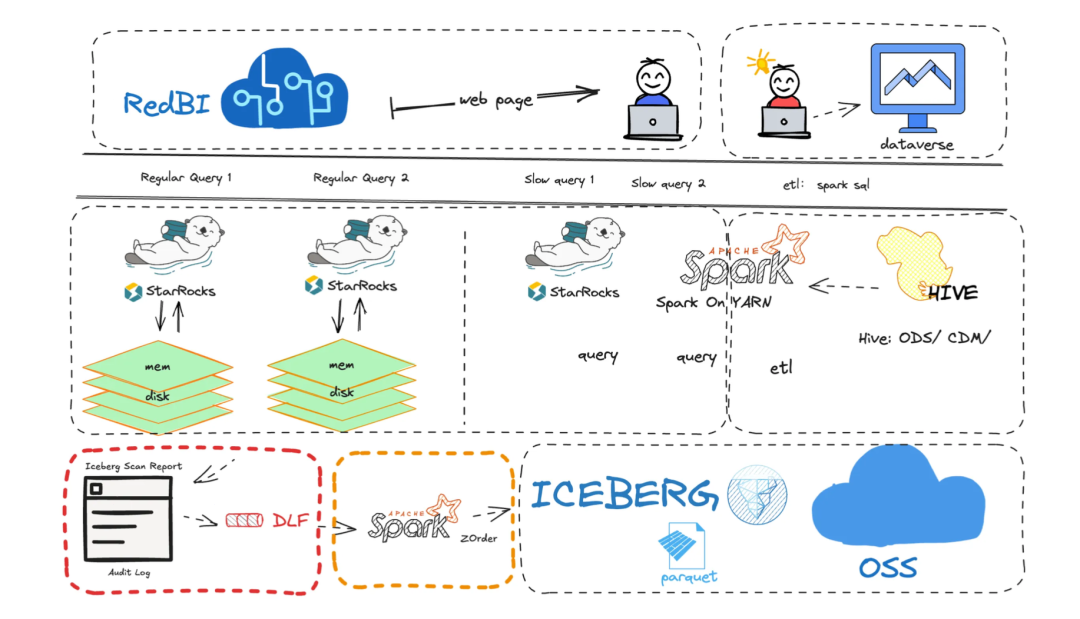
智能优化方案设计
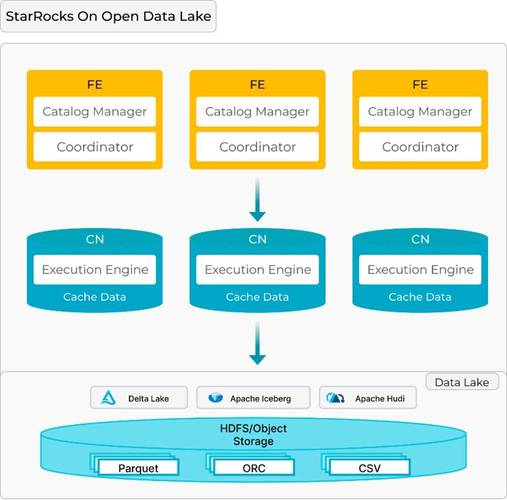
为应对数据集查询性能随时间下降问题,设计了湖上分析数据集智能优化方案。此方案从多方面入手,考虑到当前集群规模与平台性能要求,对可进行Shuffle Join的维表数量做了限制,最多支持四个维表与主表关联,确保其他数据集快速响应不受影响。
这一设计平衡了各数据集的性能需求,保证整个系统的稳定高效运行。
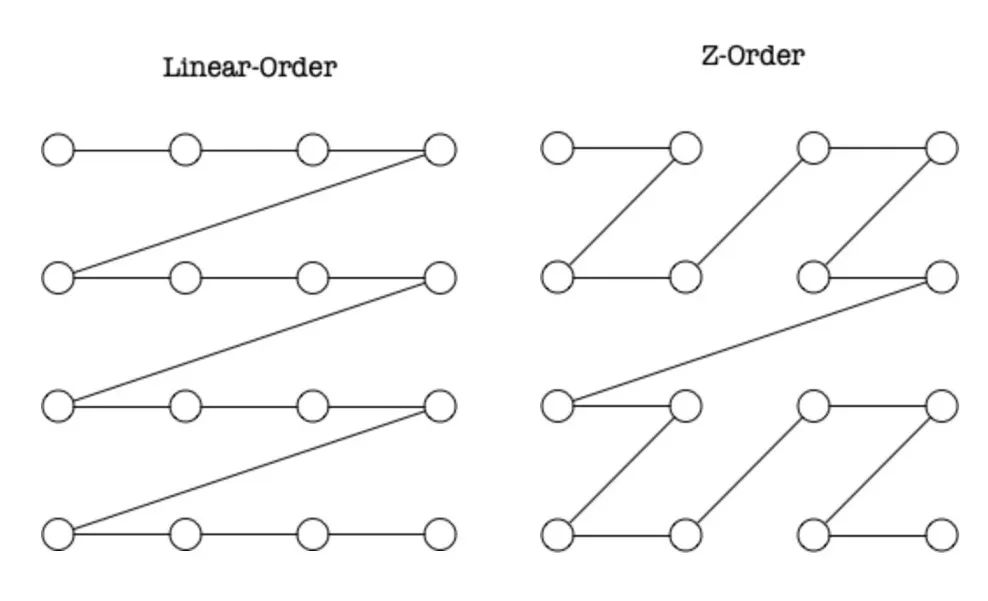
Z - Order排序优势
Z - Order能对多维数据进行有效线性排序,在某些查询模式尤其是范围查询中有出色表现。应用这种排序方式后,查询效率得到明显提升。在海量的数据集中,能快速定位所需数据,减少查询时间。
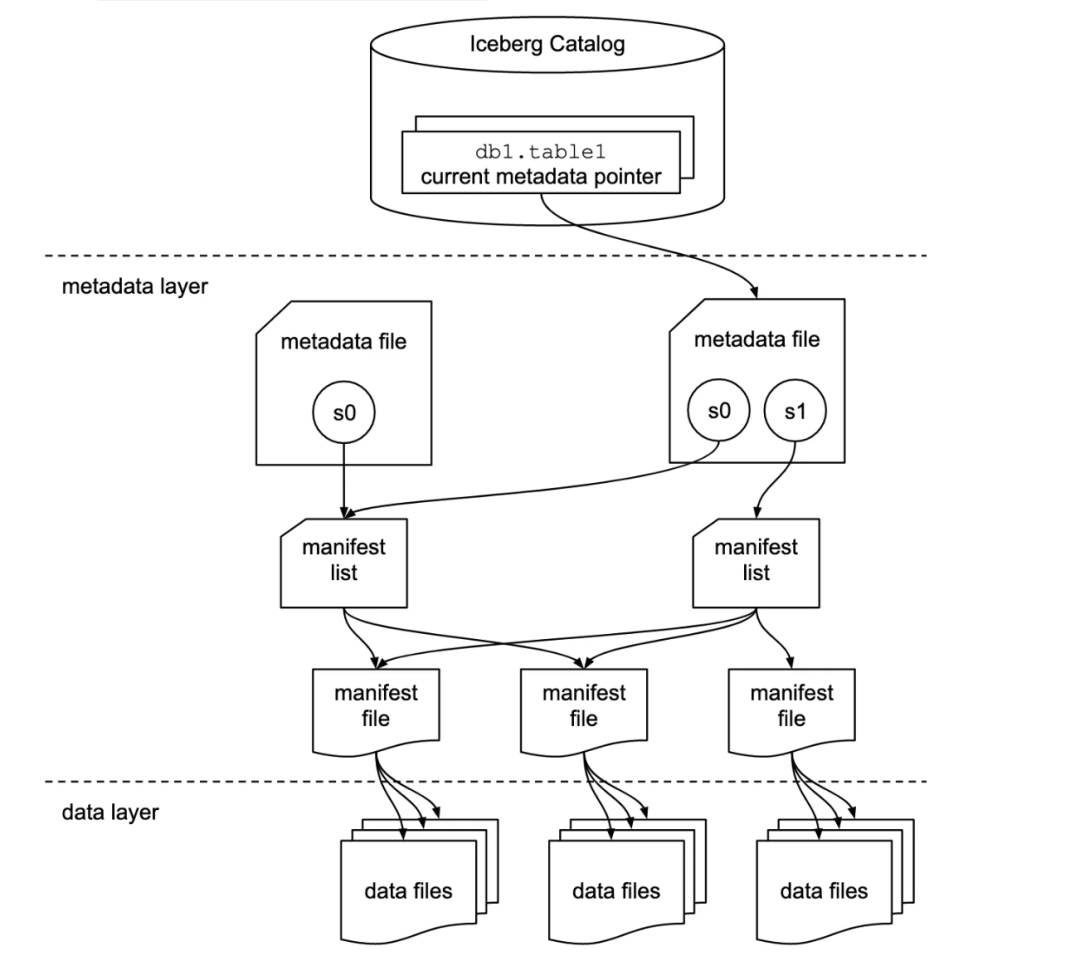
DataFile.RECORD_COUNT,DataFile.FILE_SIZE,DataFile.COLUMN_SIZES,DataFile.VALUE_COUNTS,DataFile.NULL_VALUE_COUNTS,DataFile.NAN_VALUE_COUNTS,DataFile.LOWER_BOUNDS,DataFile.UPPER_BOUNDS,...
在一些数据分析项目中,采用Z - Order排序后,范围查询的性能比之前有了质的飞跃,大大提高了数据可用性。
排序键选择更新机制

为解决ClickHouse索引键保鲜度低问题,设计了基于用户行为记录的智能排序键选择与更新机制。应用在自助分析平台上,结合分析师使用习惯和T + 1阶段反馈,及时调整排序方式。让新增数据更贴合近期用户查询模式,提升查询效率。
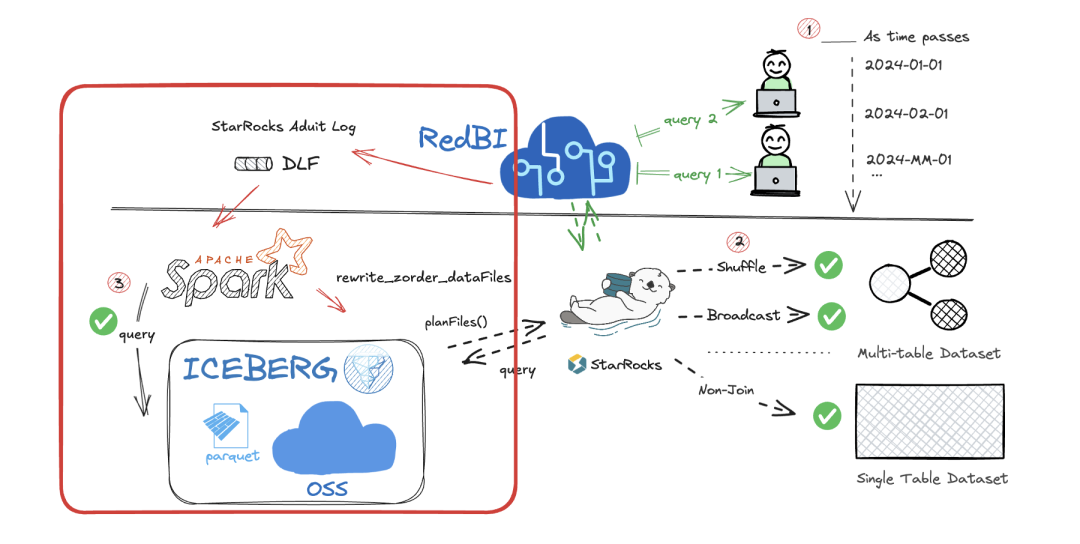
这一机制使数据集能动态适应不同用户的查询需求,提供更精准的查询服务。
平台排序列筛选
在数据湖管理平台中,排序列筛选对提升查询性能和优化存储结构很关键。筛选出的排序列是用户查询核心字段,能有效优化高频使用场景。例如在一个电商数据分析平台,筛选出交易金额、交易时间等排序列后,查询效率大幅提高。
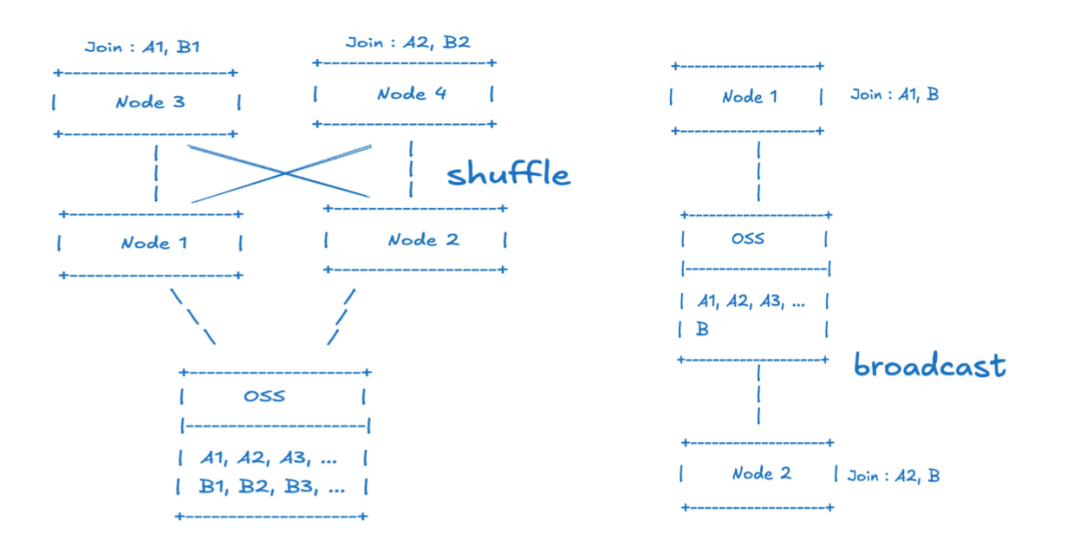
依据用户实际使用情况筛选排序列,是提升数据查询体验的重要环节。
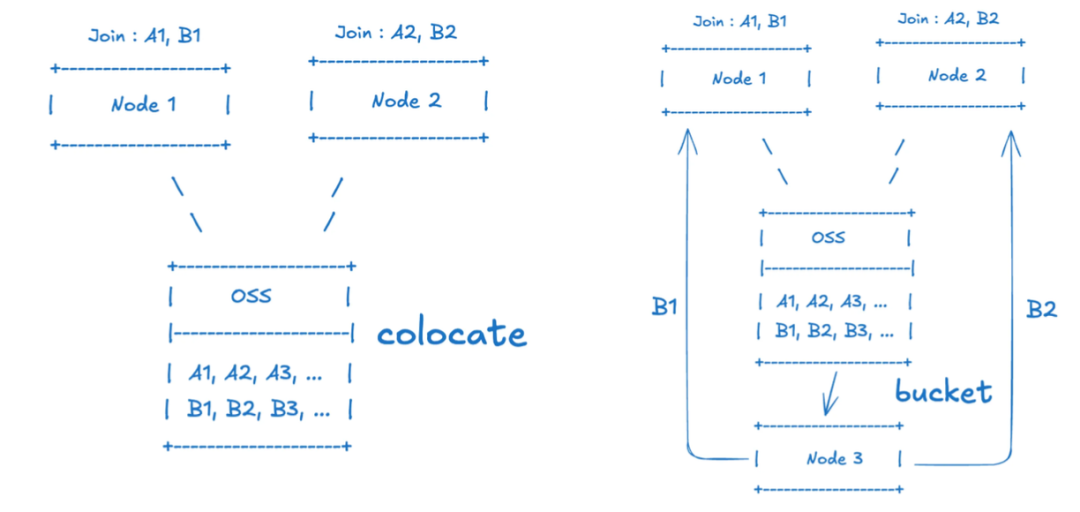
大家觉得在实际业务中,哪种优化方式对提升查询性能最有效果?欢迎评论、点赞和分享本文。







