
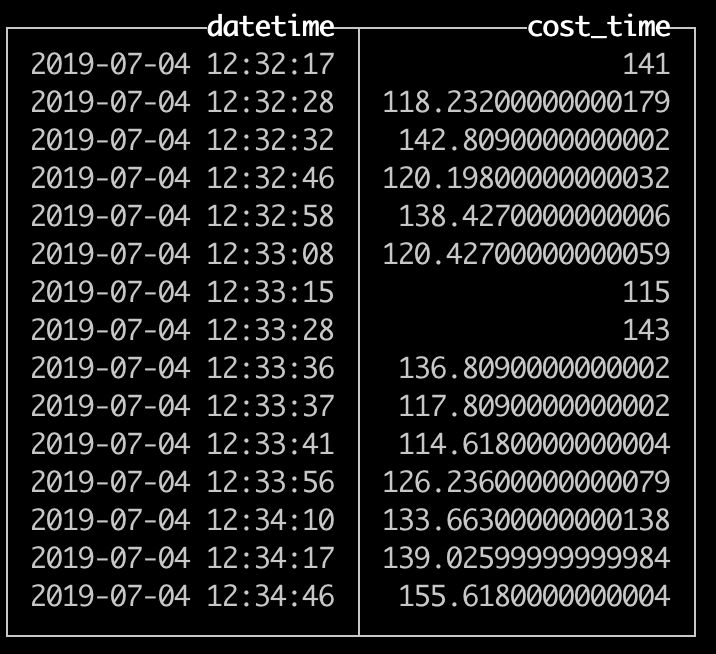
如今在数据处理领域,数据的有效管理和高效查询是重点。就像这里的ClickHouse数据库中的操作就有很多值得探索之处。
表的创建逻辑
创建名为default.ods_nginx_access_log的表时,我们定义status为字符串类型。这种定义是基于其数据性质做出的。例如在某些网站访问日志中,状态信息是文本形式存在。而按照日期进行分区,这样方便对不同日期的数据进行分别管理。比如在处理日流量统计时就很好用。
之后按照一定的顺序来构建表,像以(date, intHash64(datetime), host, port, status)顺序排列。这种顺序可能是基于常见的查询需求,比如按照时间顺序查看主机等相关访问信息。
数据抽样查询
对于该表的数据能以datetime字段做抽样查询很实用。若想抽样查询10%的数据,在SELECT查询语句中加入SAMPLE 0.1即可。例如一个大规模的日志数据集,想要快速获取大致情况,抽样10%就够了。抽样查询可以大大减少查询资源的消耗,并在数据探索阶段提供一个大概的结果。
我们可以根据不同的需求调整抽样比例。如果需要更精确一些的数据展示,可能就需要减少抽样比例,但是这也会增加查询的时间。
物化视图聚合表创建
创建名为default.dw_nginx_access_log_1s的物化视图聚合表是一个非常有效的数据组织方式。以host,port,status三个维度聚合统计每秒钟请求数。这种聚合方式能让我们快速得到关键数据。例如公司网站运维人员可以快速知道每秒钟各个主机、端口下不同状态的访问次数。
而且依据date分区和以特定顺序排列,还有使用intHash64(datetime)进行取样,能进一步优化查询效率。比如在大型业务系统下,数据处理效率能显著提升。
物化视图数据查询条件
在物化视图的查询中,有特定的时间查询条件限定。查询中WHERE (datetime >= toDateTime($from - 86400 7)) AND (datetime < toDateTime($to - 86400 7))这样的限定,确保了查询到的数据是在一定时间范围内的。这对于分析特定时间段内的业务数据很关键。
这种基于时间的数据查询在很多领域都有应用。例如电商领域分析近一周的数据来判断用户访问高峰等情况。
数据结果呈现
数据结果有像count() AS "昨天QPS"和count() AS "七日QPS"这样的呈现形式。这使得数据结果有明确的意义。比如互联网企业可以迅速知道昨天和近七日的查询率。
(intDiv(toUInt32(datetime), $interval) $interval) 1000 AS t这样的操作也有助于数据以更合理的形式呈现。例如让时间相关的数据在合理的单位呈现利于分析。
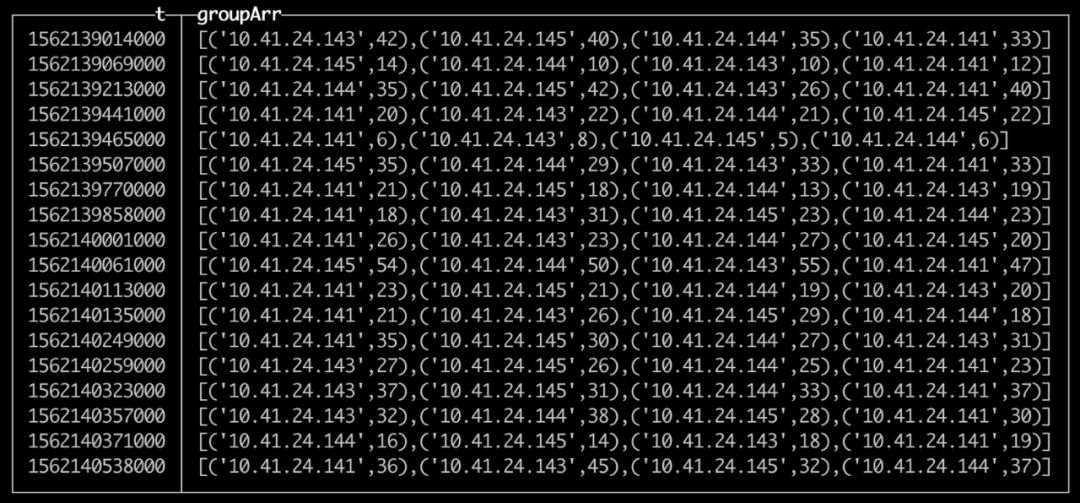
整体操作的意义
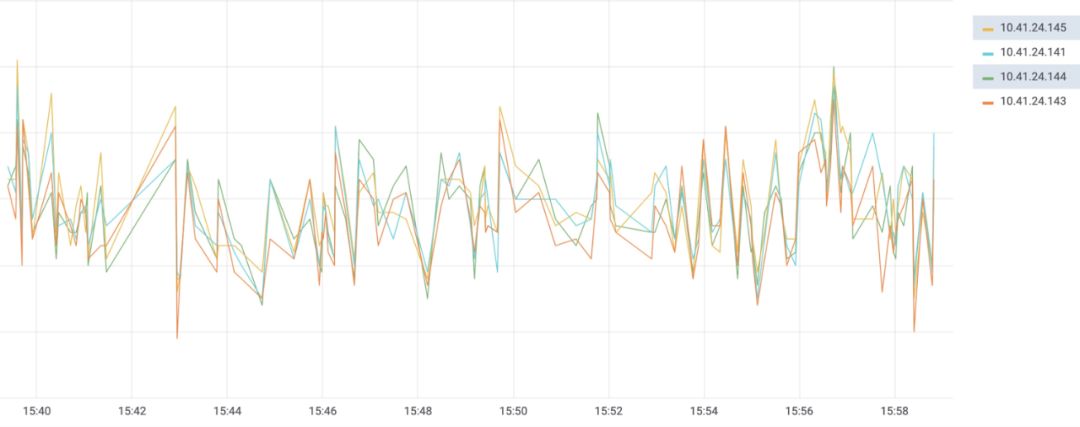
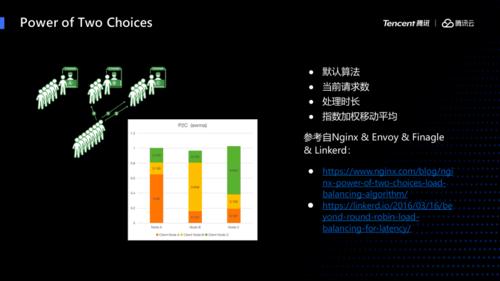
ClickHouse中的这些操作,能极大提升数据处理效率。在现代数据量爆炸的环境下,这是非常重要的。像数据密集型企业如大型互联网公司,每天产生海量数据,这些操作可以让数据工程师快速准确分析数据。
不同的操作组合起来能满足各种复杂需求,从数据创建、抽样查询到最后的结果呈现,每一步都是构建高效数据处理体系的关键。
你觉得这些操作在超大型数据处理中有哪些优势是最突出的?欢迎评论点赞分享。



