

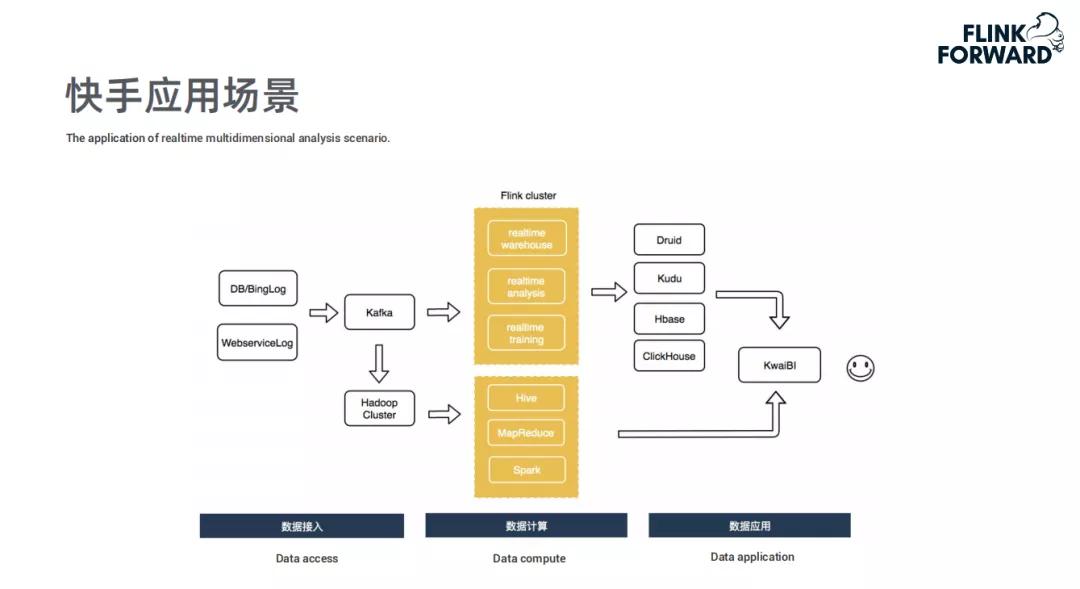
计算链路概述

快手的计算链路颇为高效,它将DB/Binlog和WebService Log实时导入Kafka,再接入Flink做实时计算。这涵盖实时数仓、实时分析和实时训练,最终结果存入Druid、Kudu、HBase或ClickHouse等数据库。就目前来看,快手主要采用的是Flink + Kudu方案。
在当下的大数据环境中,这样的链路能快速处理海量数据。例如每天快手平台上产生的数十亿条用户行为数据,都能通过该链路高效流转和计算,为后续的业务决策提供数据支持。

方案对比分析
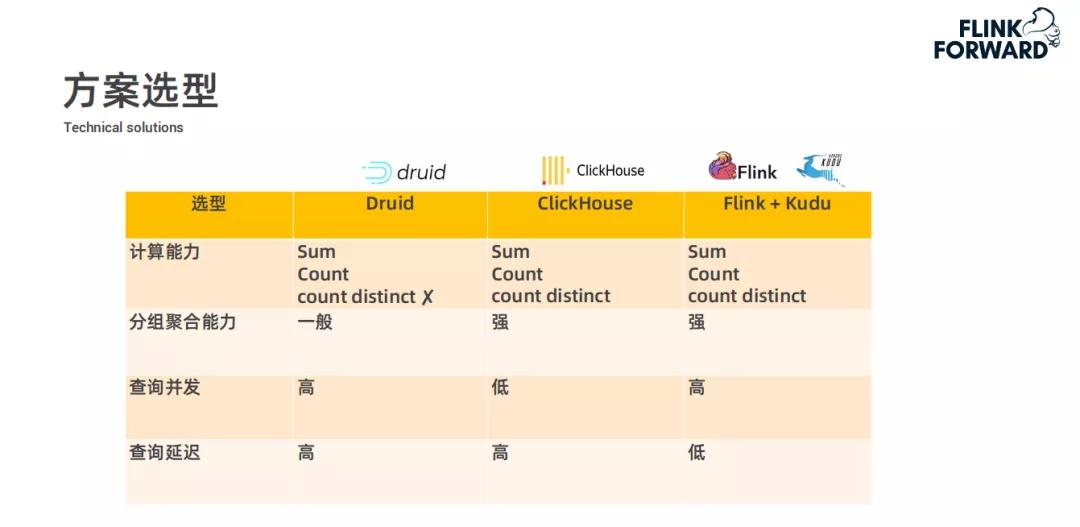
前期调研时,快手对比了多种方案,从计算能力、分组聚合能力、查询并发和查询延迟四个方面,结合实时多维查询业务场景。Flink + Kudu方案吸收了Kylin的思路,Kylin能对多个维度和指标做离线预计算并存储到HBase。而快手则通过Flink实时计算指标并写入Kudu。
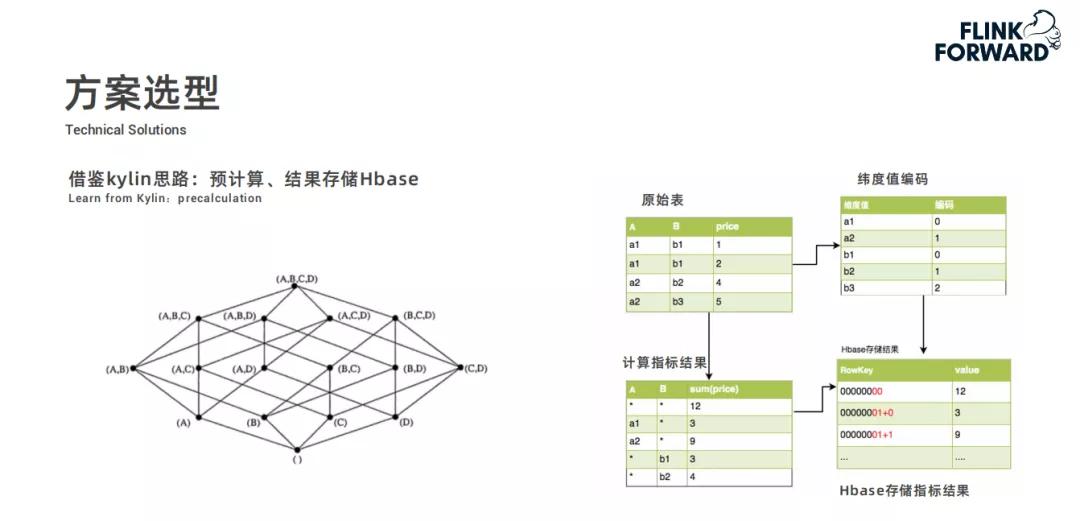
比如在分析用户互动行为时,不同方案处理的效率和效果差异明显。Flink + Kudu方案在计算速度和结果准确性上,相比其他方案表现出了一定的优势,能更及时地反馈出数据变化。
实时多维分析流程
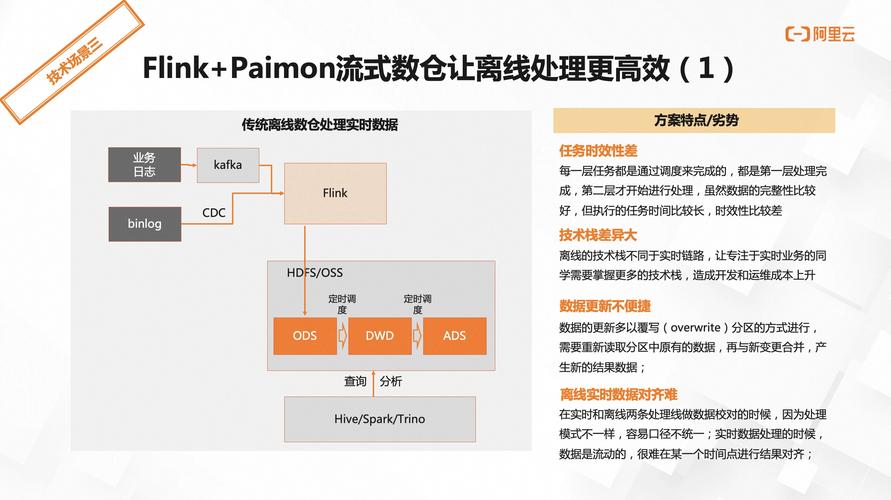
实时多维分析流程有其独特性。用户在快手自研的BI分析工具KwaiBI上配置Cube数据立方体模型,指定好维度列、指标列以及计算规则。选取的数据表是经处理后存于实时数仓平台的数据表。随后Flink任务会按规则对建模指标进行预计算,结果存入Kudu。
以分析不同地区用户的观看习惯为例,用户可以在KwaiBI上灵活配置想要分析的维度和指标,通过Flink快速完成计算,将结果存储后便于后续更深入的研究。
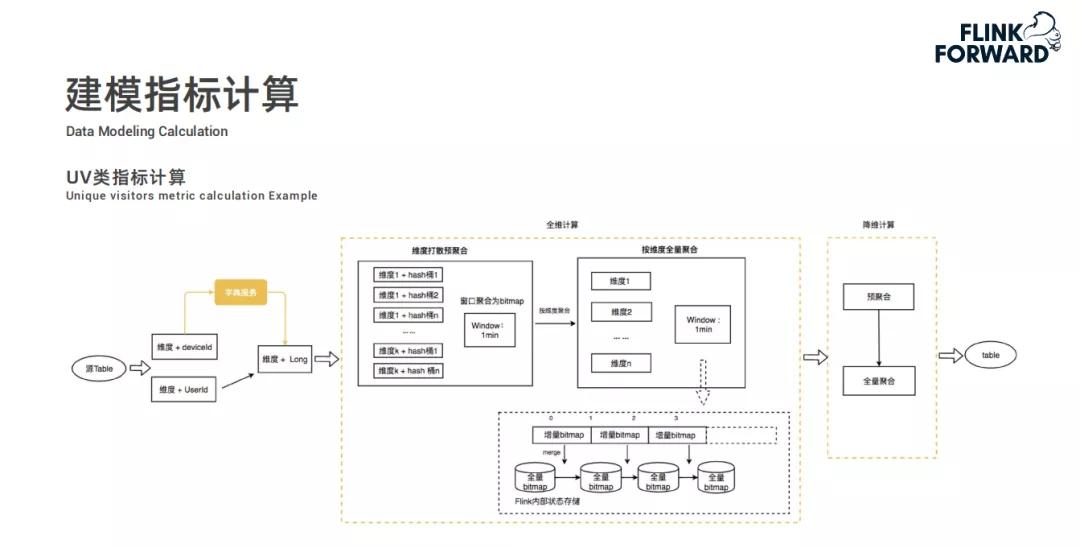
维度数据倾斜解决
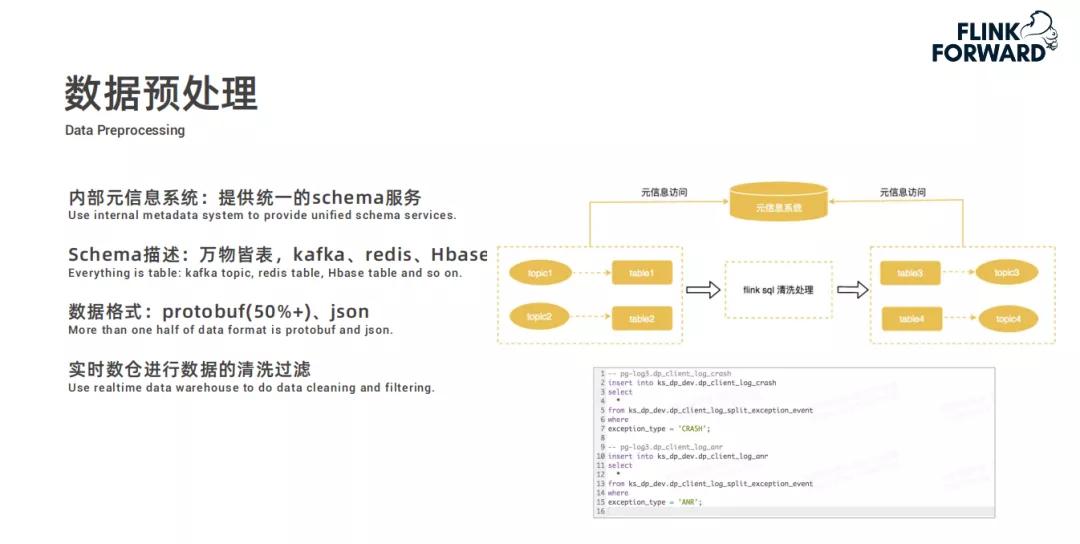
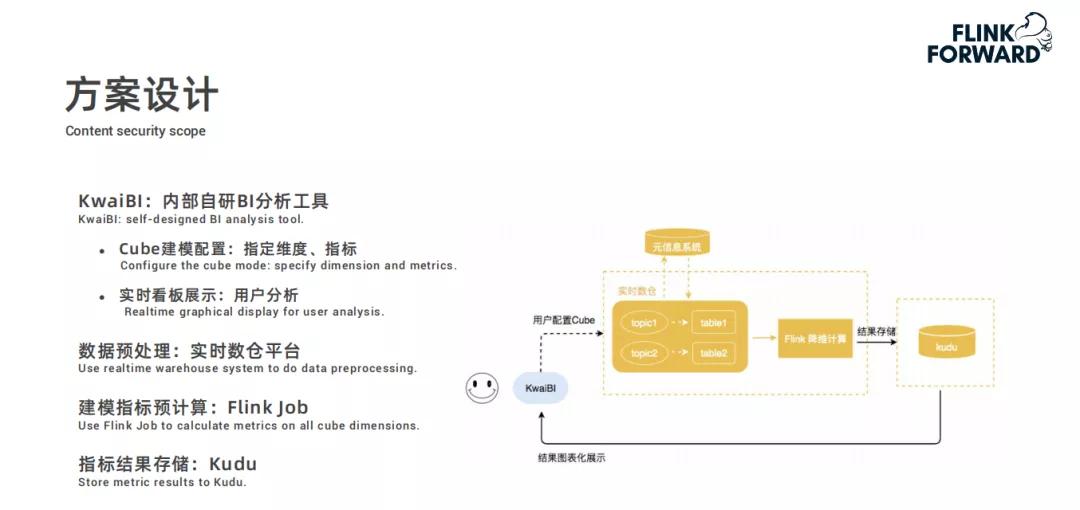
在建模指标计算里,维度数据倾斜是个问题,快手采用预聚合和全量聚合两种方式解决。预聚合通过相同维度hash打散,全量聚合则是将相同维度打散后再聚合。
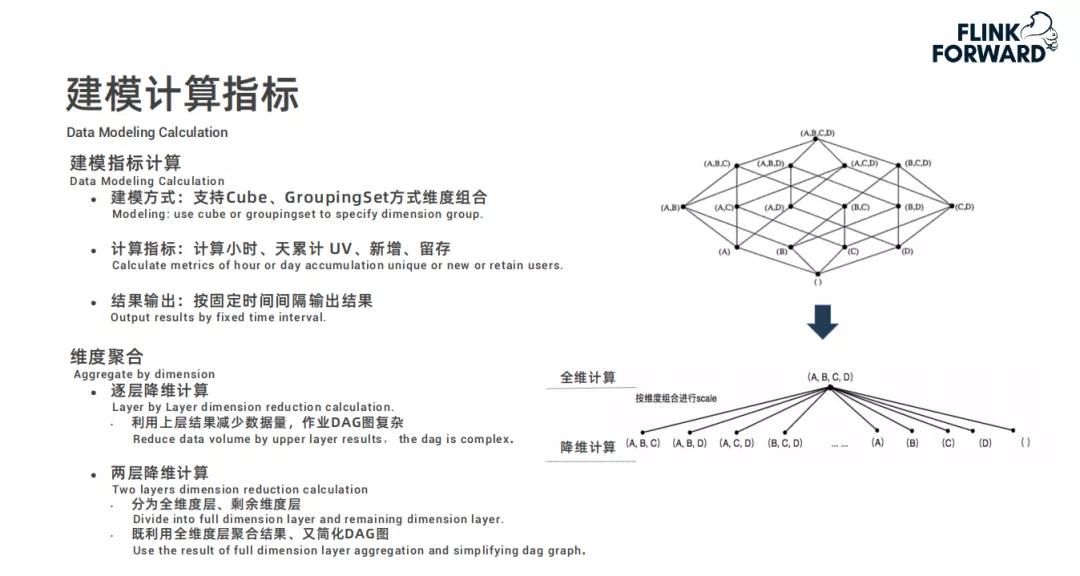
因为在实际的数据计算中,有些热门维度的数据量会远远超过其他维度,这就容易导致计算资源分配不均。通过这两种聚合方式,能确保计算过程更加平稳,提高计算效率。
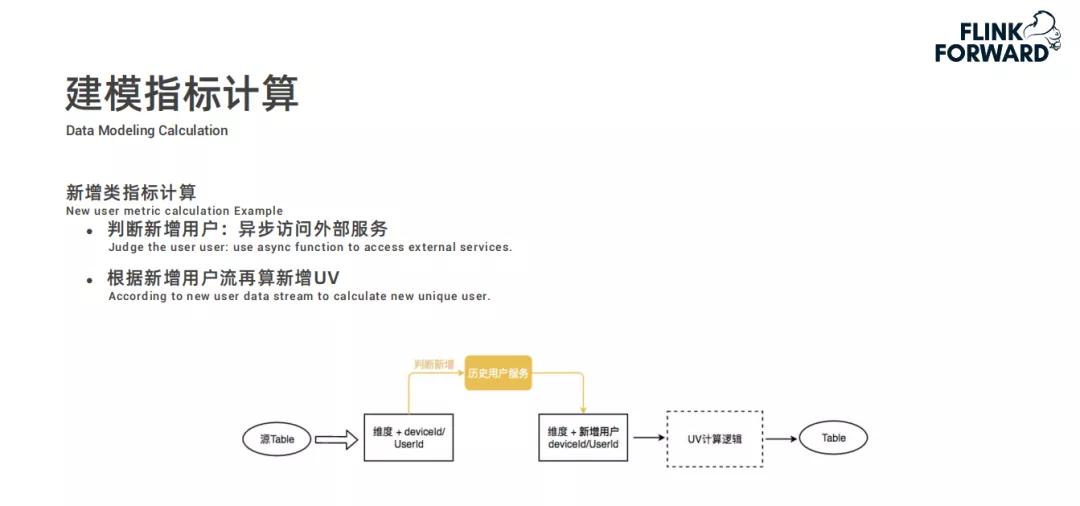
新增指标计算逻辑

新增类指标计算和UV计算有所不同。它需要判断是否为新增用户,通过异步访问外部的历史用户服务来确定,之后结合新增用户流计算新增UV,计算逻辑和UV计算一致,最后结果存储到Kudu。
比如在新活动上线时,分析新增用户的相关数据就显得尤为重要。这种计算逻辑能够准确筛选出有价值的数据,帮助运营人员评估活动效果。
存储与模型训练
在存储方面,对维度编码,以时间+维度组合+维度值组合为主键,按维度组合、维度值组合、时间分区,提高查询效率。另外,SlimBase数据会实时Join,将结果作为样本用于模型训练,训练后的模型推送到线上广告服务。
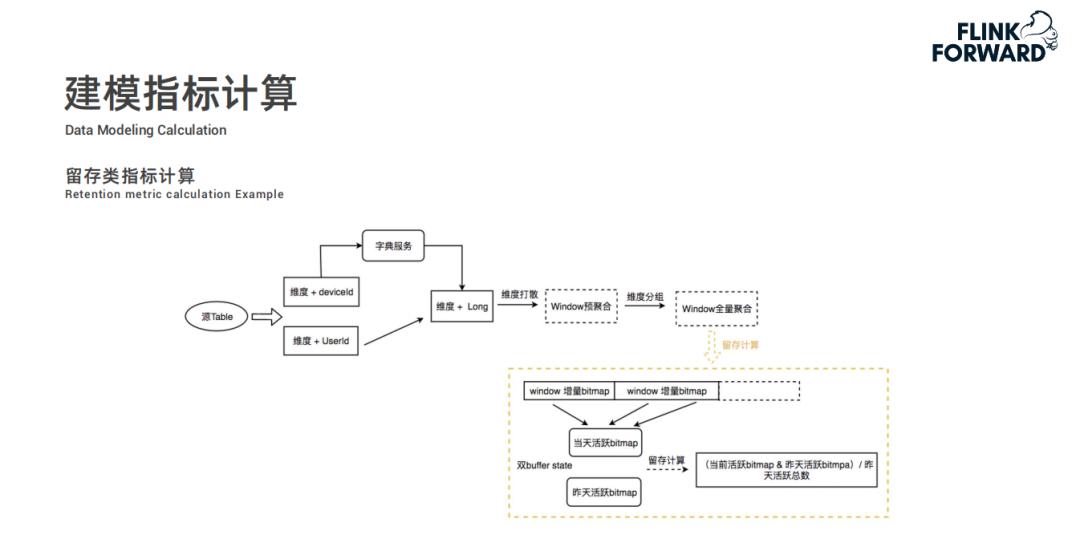
如此存储方式让查询更加快捷,能在短时间内获取所需数据。而实时Join数据用于模型训练,能不断优化广告投放效果,为平台带来更多商业价值。

你觉得快手这种计算链路和分析方案在未来还会有哪些发展方向?点赞并分享本文,让更多人了解快手的技术亮点,同时也欢迎在评论区说出你的想法。



