

闲鱼搜索现状痛点 /b>
闲鱼主搜目前仅一条链路支持多业务发展,各角色、业务和节点是高耦合串行迭代模式。这种模式限制了业务的灵活性,难以安全、高效地支撑多业务接入,并且不同业务的混排能力也严重不足。就像一条单行道,车一多就容易拥堵。
随着闲鱼业务的不断拓展,现有模式已经难以满足需求。比如新业务上线,会受到旧业务的影响,难以快速迭代,导致业务发展受限。
主要模块介绍 /b>
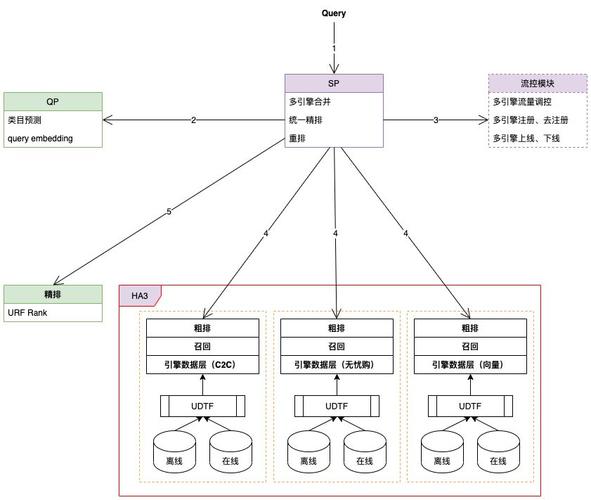
Blender是SP服务核心入口,负责解析用户query意图、引擎分页召回、搜索数据补齐等。比如当用户搜索“手机”,它能确定用户需求,召回相关商品信息。
Uniq_session是召回核心入口,通过引擎召回、分页处理、URF Rank等获取商品列表。以搜索衣服为例,它会将符合条件的衣服按一定规则排列展示给用户。
搜索引擎体系 /b>
闲鱼搜索很多场景依靠集团搜索中台能力。其搜索引擎包括数据源聚合、全量/增量/实时索引构建及在线服务等部分。在实际运作中,会对大量商品数据进行处理,比如每天离线dump数亿条商品信息来构建数据源。
集团内部经过一系列处理阶段,为客户提供高可用高性能搜索服务。例如能快速响应用户搜索请求,在短时间内返回准确结果,保障了用户的搜索体验。
开发工具与引擎 /b>
SP/SPL是集团内基于Wunder的开发工具,提供开发测试打包上线界面和业务函数库。开发人员可以借助它更快地完成开发工作。
HA3是基于suez框架的全文检索引擎,提供多种查询、过滤、排序、聚合子句,还支持自定义开发排序插件。商家可以根据自己的需求定制排序规则,让商品更精准地展示给用户。
问题解决思路 /b>
要解决安全、灵活、高效支撑多业务接入并实现混排能力的问题,重新设计并执行闲鱼底层引擎召回逻辑升级。将单引擎单路召回架构升级为多引擎多路并发召回架构。这种架构就像多条车道并行,大大提高了通行效率。
在具体操作中,流控模块从配置中心获取引擎定制化配置,执行query改写生成HA3请求串,还会依据query携带的多引擎标识并发请求不同引擎在线服务召回商品并合并结果。这样能精准地为用户提供各业务的商品。
升级带来的好处 /b>
多引擎隔离和query改写让各业务有效解耦,满足定制化需求,对闲鱼主搜服务干扰最小。比如无忧购业务能有独特的商品展示规则,主搜业务不受其影响。
-- 构建请求的biz列表
function get_search_biz_type_list(query, param)
-- 搜索biz配置列表
local search_biz_type_list = {}
if query.bizType then
if type(query.bizType) == "string" then
table.insert(search_biz_type_list, query.bizType)
else
search_biz_type_list = query.bizType
end
end
if search_biz_type_list == nil or #search_biz_type_list < 1 then
table.insert(search_biz_type_list, param.default_biz_type)
end
local search_list = {}
if not query._enable_multiplexed then
table.insert(search_list, {biz = param.default_biz_type, biz_type = search_biz_type_list})
return search_list
end
for _, type in ipairs(search_biz_type_list) do
table.insert(search_list, {biz = type, biz_type=type})
end
return search_list
end
集成dianmond配置中心的流控模块,能实时干预query搜索能力并孵化创新业务。以闲鱼无忧购创新业务为例,它可以根据市场需求快速调整搜索策略。
大家觉得闲鱼这种搜索架构升级方案在其他电商平台是否也适用?欢迎在评论区留言分享你的看法,也别忘了点赞和分享本文!
function parse_diamond_config(query, param)
query._cluster_info = {}
-- 多引擎配置
local cluster_info_str = param.cluster_info
local cluster_info = setup.split(cluster_info_str, ";")
if not cluster_info then
return
end
for _, info in ipairs(cluster_info) do
local single_cluster_info = setup.split(info, ":")
if single_cluster_info and #single_cluster_info > 1 then
query._cluster_info[single_cluster_info[1]] = single_cluster_info[2]
end
end
end



