

Python作为当下热门语言,许多人学会基本语法后却不知去哪找案例练习。下面以QQ空间操作为例,介绍如何用Python开展实践。
def search_cookie():
qq_number = input('请输入qq号:')
if not __import__('os').path.exists('cookie_dict.txt'):
get_cookie_json(qq_number)
with open('cookie_dict.txt', 'r') as f:
cookie=json.load(f)
return True
def get_cookie_json(qq_number):
password = __import__('getpass').getpass('请输入密码:')
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
login_url = 'https://i.qq.com/'
chrome_options =Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get(login_url)
driver.switch_to_frame('login_frame')
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="u"]').send_keys(qq_number)
driver.find_element_by_xpath('//*[@id="p"]').send_keys(password)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="login_button"]').click()
time.sleep(1)
cookie_list = driver.get_cookies()
cookie_dict = {}
for cookie in cookie_list:
if 'name' in cookie and 'value' in cookie:
cookie_dict[cookie['name']] = cookie['value']
with open('cookie_dict.txt', 'w') as f:
json.dump(cookie_dict, f)
return True
def get_g_tk():
p_skey = self.cookie['p_skey']
h = 5381
for i in p_skey:
h += (h << 5) + ord(i)
g_tk = h & 2147483647
登陆准备
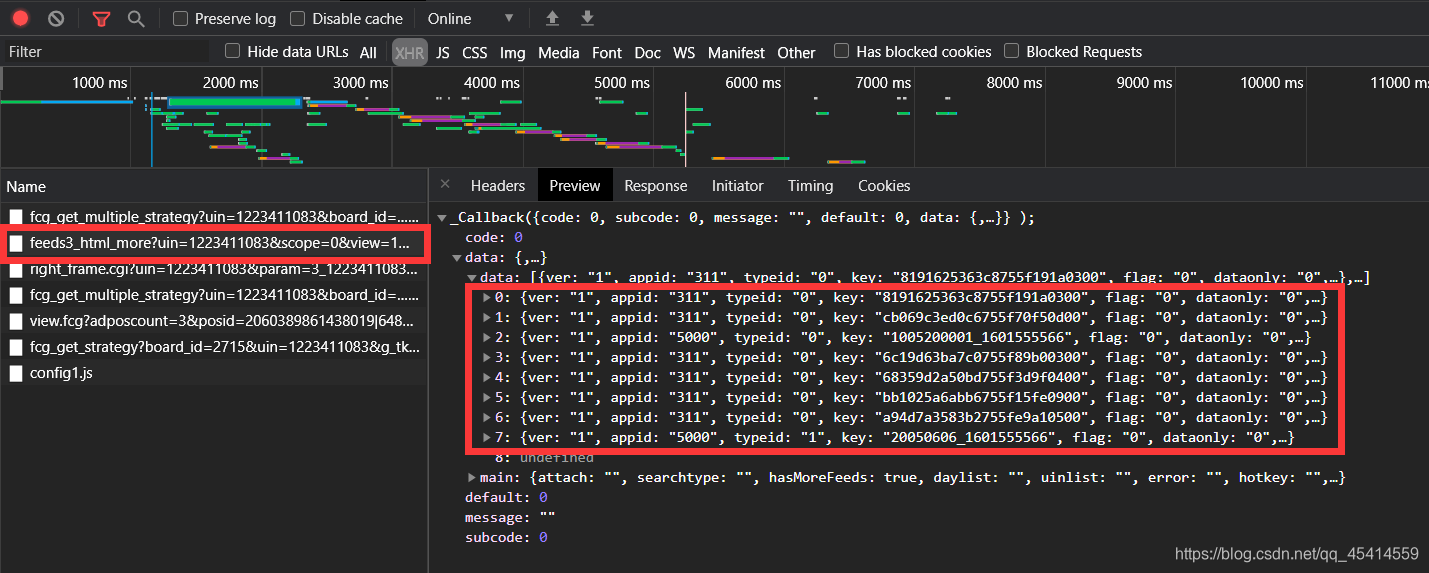
若要对QQ空间进行操作,需先处理登陆问题。上几期已介绍过相关内容,本文不再赘述。当获取到cookie信息和g_tk参数后,就可继续探寻空间好友动态的XML位置,为后续操作做好铺垫。
寻找XML
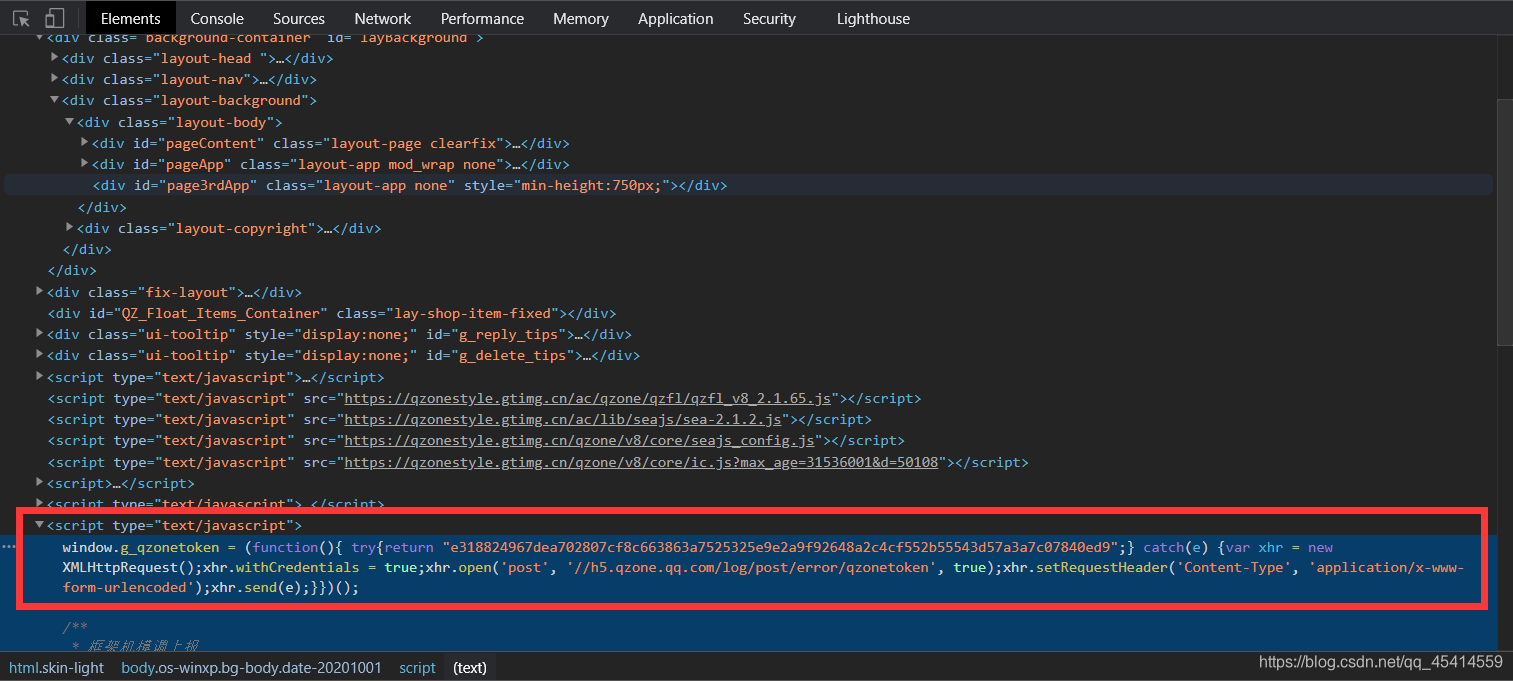
获取必要信息后,开始寻找空间好友动态XML。可逐步点到XML位置逐个查找,在一番尝试后,会发现“feeds3_html_more”较像目标。点进去确认,这就是我们要找的URL链接。不过该链接所需参数较多,需进一步探究。
def get_space():
your_url = 'https://user.qzone.qq.com/' + str(qq_number)
html = requests.get(your_url,headers=headers,cookies=cookie)
if html.status_code == 200:
qzonetoken = re.findall('window.g_qzonetoken =(.*?);',html.text,re.S)[1].split('"')[1]
return True
参数解析
'rd': '0.9311604844249088',
'windowId': '0.51158950324406',
'usertime': str(round(time.time() * 1000)),
对于链接所需参数要详细分析。qzonetoken参数在源码中是可变“定值”,每次刷新会改变,但源码有具体值。而windowId与rd经多次实验发现,它们对整体影响不大,可直接抄用。掌握这些参数特性,利于后续操作。
def get_g_tk():
p_skey = self.cookie['p_skey']
h = 5381
for i in p_skey:
h += (h << 5) + ord(i)
g_tk = h & 2147483647
网页访问与处理
拿到XML及各参数后,就可以访问网页获取返回值。但这个返回值与其他的不同,它不只是个json文件,不能直接转成字典格式使用,这有点麻烦。获取字符串后,先把前后不一致的切片扔掉,经过一系列处理,难以转换为字典格式。
数据提取
此时可以用demjson将字符串转换为字典格式。接着,提取其中data的data,这里是前八条动态的参数,我们只需第一个说说的动态信息。从这些信息中,可提取名字、QQ号、发布时间等我们想了解的内容。
# 例子
# -*- coding: utf-8 -*-
import demjson
js_json = "{x:1, y:2, z:3}"
py_json1 = "{'x':1, 'y':2, 'z':3}"
py_json2 = '{"x":1, "y":2, "z":3}'
data = demjson.decode(js_json)
print(data)
# {'y': 2, 'x': 1, 'z': 3}
data = demjson.decode(py_json1)
print(data)
# {'y': 2, 'x': 1, 'z': 3}
data = demjson.decode(py_json2)
print(data)
# {'y': 2, 'x': 1, 'z': 3}
点赞操作及优化
处理完说说信息,来看看点赞操作。清空原有动态抓包,点个赞可发现关于dolike的URL有三个,第一个POST请求就是点赞网址。获取URL后,找到所需参数。opuin是自己QQ号,可从代码提取;unikey与curkey是被点赞方说说链接,前面已获取。不过由于一些原因,这个代码无法实现绝对秒赞。可以在本地建文件,写入最后一条说说时间戳,对比当前时间戳和空间第一条说说,判断有无更新。点赞后重写文件,方便下次实现秒赞。
text = html.text[10:-2].replace(" ", "").replace('\n','')
json_list = demjson.decode(text)['data']['data']
qq_spaces = json_list[0]
你在使用Python做项目实践时,还遇到过哪些难题?欢迎评论区分享,觉得文章有用别忘了点赞和分享!
content = str(qq_spaces['html'])
try:zanshu = re.findall('(.*?)人觉得很赞 



