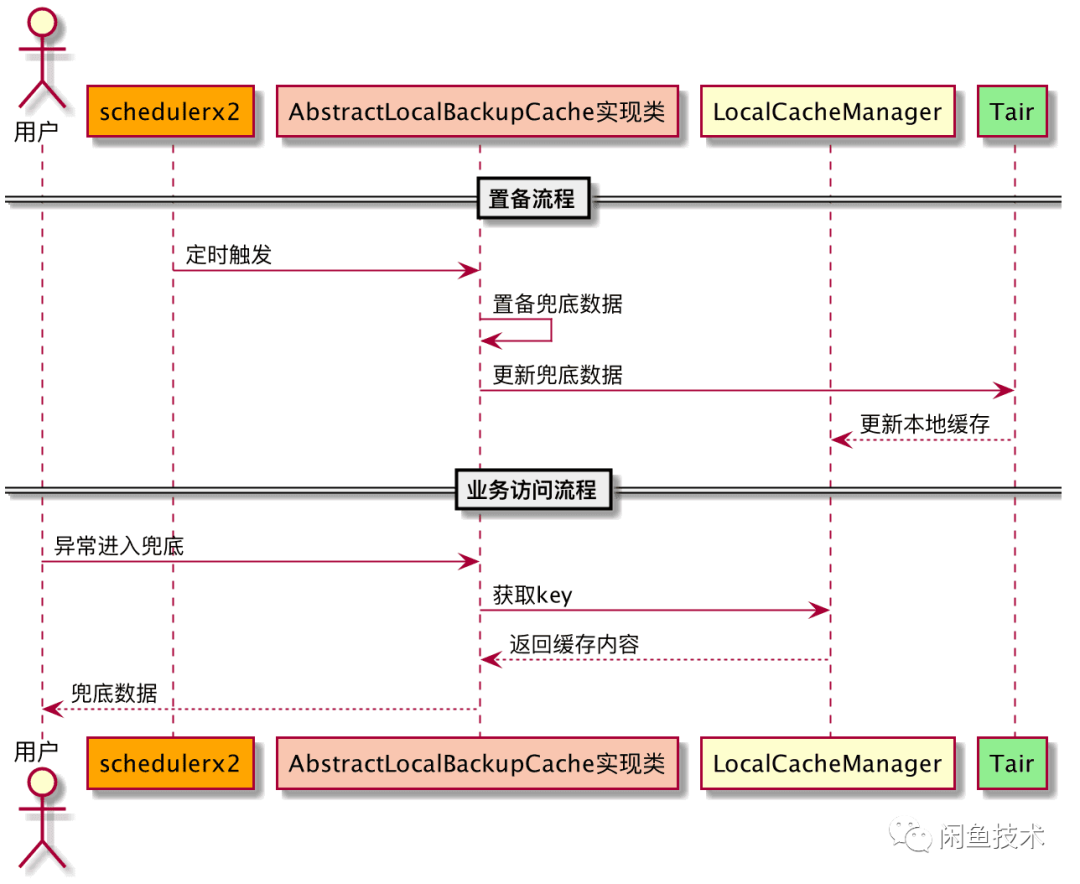
在技术领域,数据处理和缓存策略至关重要,特别是在面对断网演练等复杂情况时,选择合适的本地缓存方案十分关键!下面就详细说说本地缓存相关的那些事。
断网演练引发思考
在阿里进行断网演练时,某个区域的所有服务不可用。这种极端情况使得在技术选型时,分布式缓存Redis、Memcache等方案被排除。因为一旦网络中断,这些依赖网络的分布式缓存就无法正常工作,这就促使我们将目光投向本地缓存库。
本地缓存不受网络限制,可以在本地节点独立运行,即使在断网等异常情况下,也能保证部分数据的可用性和业务的正常运转,所以本地缓存成为解决断网演练环境下数据使用问题的重要方向。
多样的本地缓存库
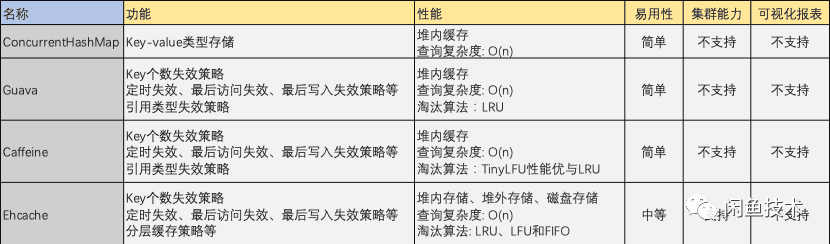
目前就业界来说,有不少本地缓存库,像Guava、Caffeine、Ehcache、Cache2K、ConcurrentHashMap、Varnish、JackRabbit等。这些库各有特点和适用场景,为技术人员提供了多种选择。
不同的本地缓存库在功能、性能、易用性等方面存在差异。比如Guava在通用场景下表现出色,Ehcache有较强的集群能力等,这就需要结合具体业务需求来挑选最适合的缓存库。
多维度对比缓存库
从功能上看,部分缓存库支持定时失效、最后访问失效、最后写入失效等策略。像除了ConcurrentHashMap外,其他几个组件都有定时失效能力,且时间复杂度都是O(n)。
在性能上,不同的缓存库处理数据的速度和效率有别。有些在高并发场景下表现稳定,有些则在数据量较大时更有优势,这需要通过实际测试和压测来验证其性能指标。
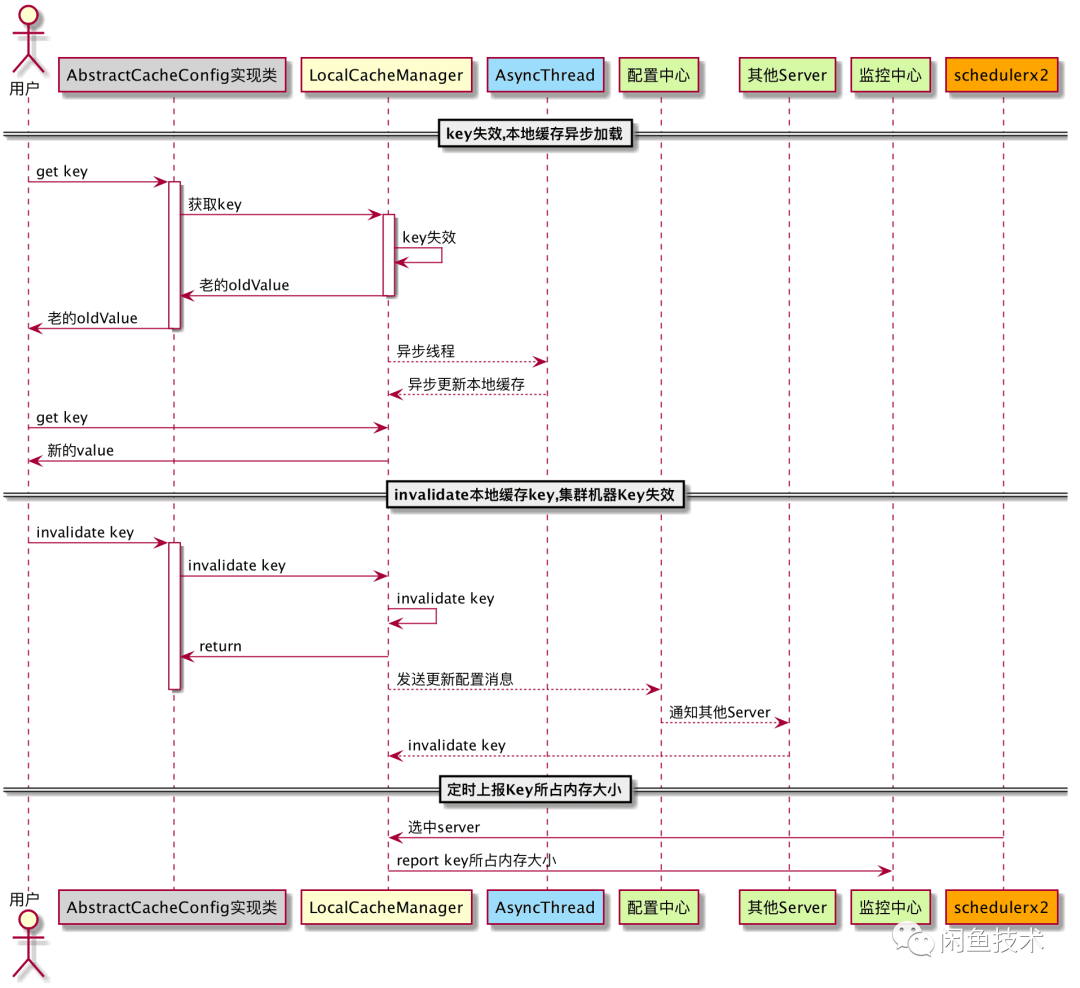
集群能力分析
在集群能力方面,Ehcache依赖自身网络协议保证集群数据一致性,但不能使用现有集团内部组件保证数据一致性。而其他缓存库在集群环境中的表现也各不相同。
集群环境中数据的一致性和同步性是关键问题。如何在多个节点间高效地同步缓存数据,避免数据不一致导致的业务问题,是选择缓存库时需要重点考虑的因素之一。
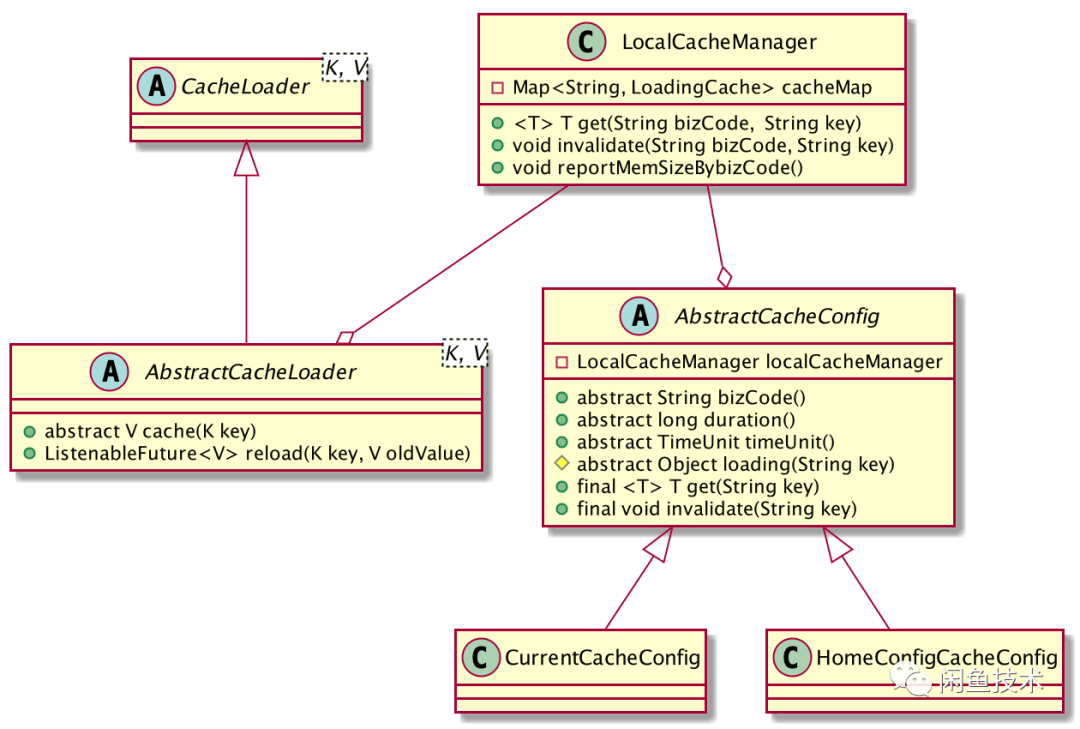
选定Guava组件
最终经过多番考量,选用了Guava组件作为本地缓存组件。因为它更加通用,并且很方便与阿里内部中间件集成配合使用。
Guava Caching提供了多种失效策略,主要使用了定时失效能力。在首次写入Key后,指定时间过后,该Key会失效,业务获取该Key时,会调用reload方法重新同步加载该Key,这满足了业务的实际需求。
集群本机Cache应用
在原来Guava Cache本地缓存能力上结合Spring自动注入能力,进行工程化,添加了业务所需的相关能力。业务同学在使用集群本机Cache组件时,只需继承AbstractCacheConfig抽象类,声明为Bean,即可使用该组件,无需关心集群环境问题。
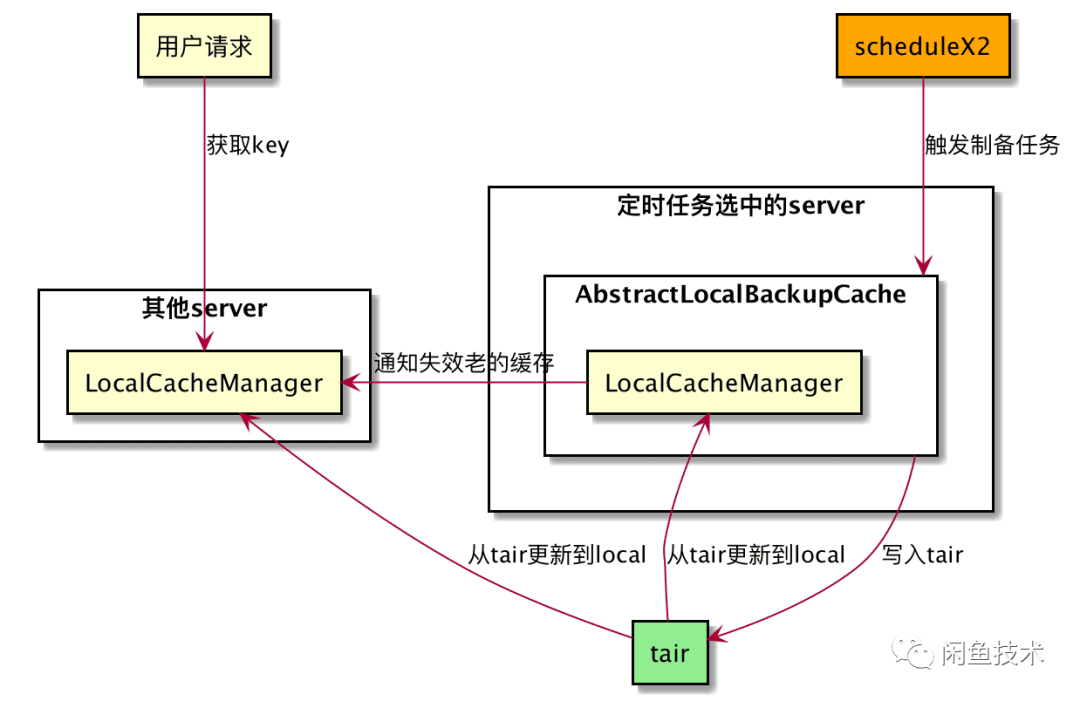
集群本机Cache组件相比Guava cache,提供了集群本机Cache Key失效能力,以及对Key集中管理和监控,减少了单独使用Guava cache带来内存无法管理的问题。不过在使用过程中,也会出现如缓存错误配置等问题,需要后续改进。