在服务端数据冗余的背景下,本地缓存的合理选择和应用至关重要。就像阿里断网演练那样,特定区域服务不可用的状况下,本地缓存如何发挥作用,哪种才是最优选,值得深入探讨。
断网演练困境
在阿里的断网演练时,某个区域所有服务陷入不可用的状态。这种情况下,常见的分布式缓存,如Redis、Memcache等,在技术选型时被笔者排除。因为演练的场景意味着部分区域服务失联,分布式缓存依赖网络通信的特性,难以保证数据的稳定获取,本地缓存成为更靠谱的选择。
本地缓存库盘点
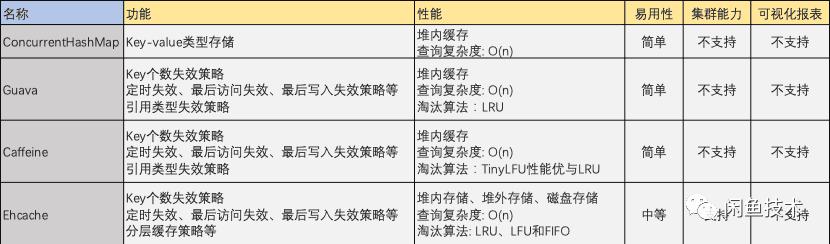
就业界而言,存在诸多本地缓存库,如Guava、Caffeine、Ehcache、Cache2K、ConcurrentHashMap、Varnish、JackRabbit等。笔者从中挑选出几个性能优越的缓存库进行对比。这些缓存库各自有着不同的特点和适用场景,了解它们是选出合适本地缓存的基础。
多维度性能对比

从功能、性能、易用性、集群能力、可视化报表等维度上看,不同的缓存库有不同的表现。在定时失效策略上,除了ConcurrentHashMap,其余几个工具都具有定时失效能力,且时间复杂度均为O(n)。这说明在定时失效功能方面,大部分缓存库处于同一水平。
集群能力差异
在集群能力方面,Ehcache依赖自身网络协议来保证集群数据一致性,却不能借助现有集团内部组件。这在一定程度上限制了其使用的便利性和效率,与其他缓存库相比,在兼容和利用现有资源上表现欠佳。
Guava组件优势
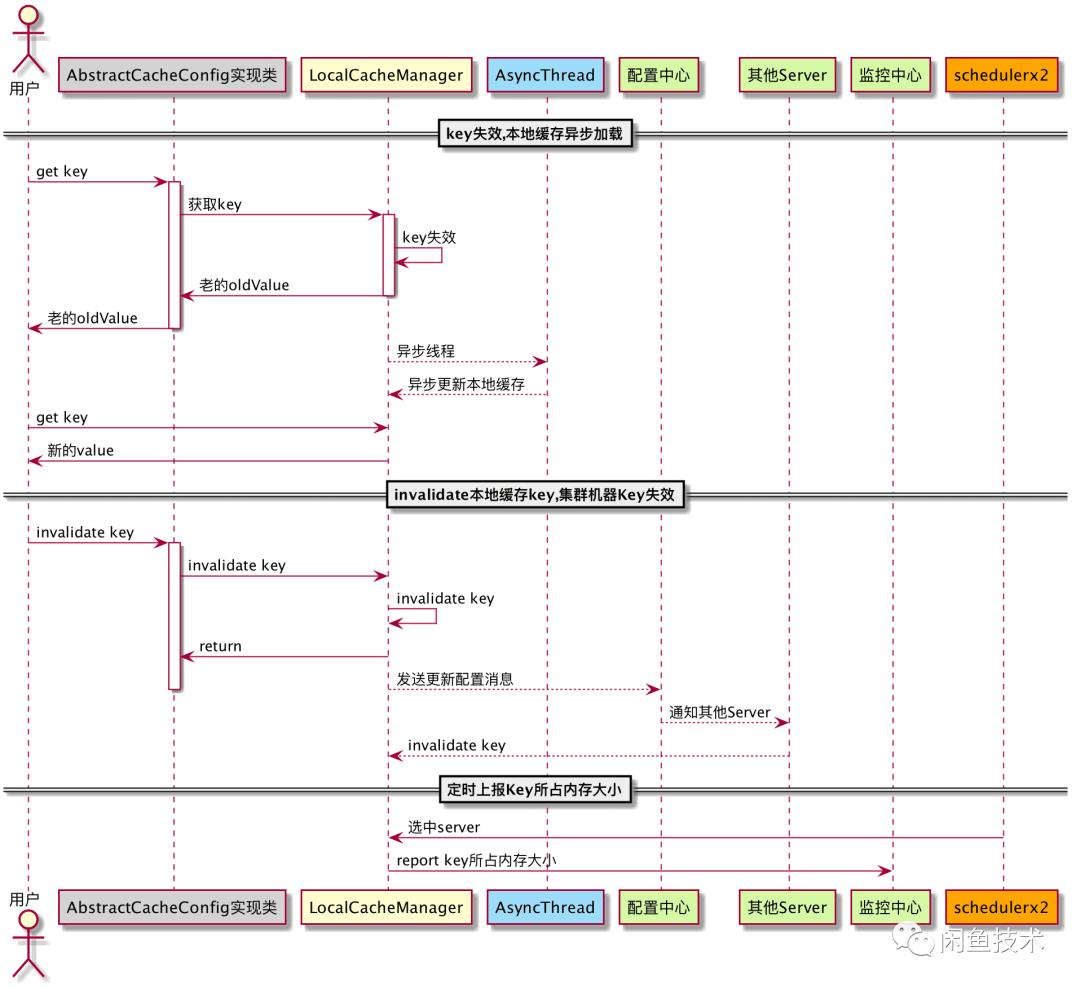
综合考量后,笔者选择了Guava组件作为本地缓存组件。一方面,它更加通用;另一方面,能方便地与阿里内部中间件集成配合。Guava Caching具备多种失效策略,像定时、最后访问、最后写入等,笔者主要使用定时失效能力,能精准管理数据的生命周期。
工程化能力拓展

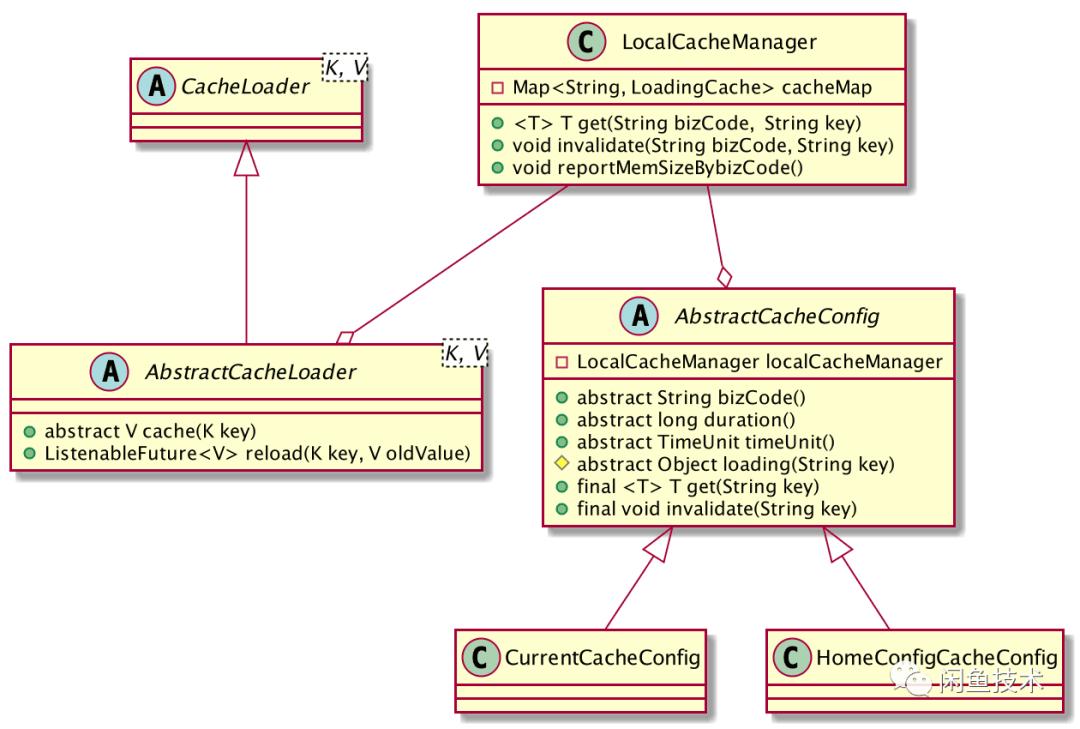
笔者对Guava Cache进行了工程化处理,结合Spring自动注入能力,增添了三种业务所需能力。业务同学使用集群本机Cache组件时,只需继承AbstractCacheConfig抽象类并声明为Bean,无需操心集群环境问题。而且它相比Guava cache,能更好地管理内存,还提供Key失效和集中管理监控功能。
典型案例应用
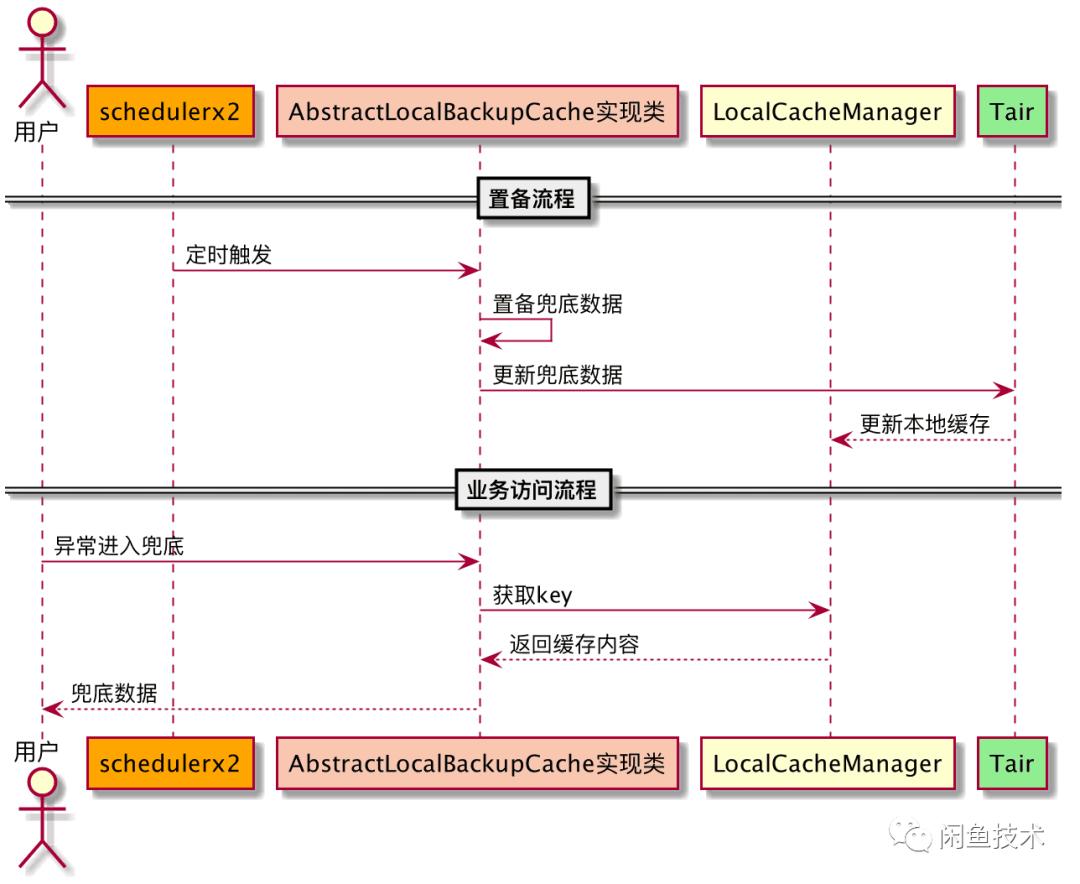
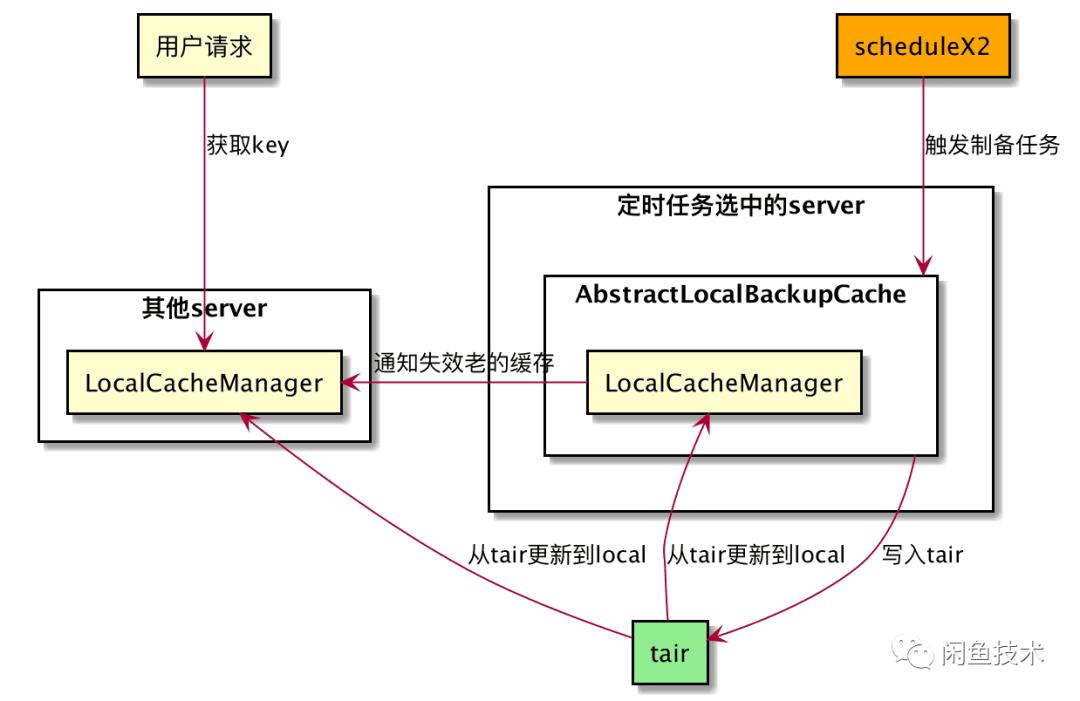
自动置备兜底组件这一典型案例就使用了集群本机cache的本机缓存和集群失效能力,轻松完成兜底数据置备。使用场景多在系统需要备用数据或者实时数据获取失败的时候,发挥了重要的保障作用。
现存问题待解
不过在使用过程中也暴露出一些问题,比如有时候集群本机cache会缓存错误配置,只能通过重启集群或者等待key失效解决。因此,集群本机cache组件的web管理功能亟待完善,以便在出现问题时能及时调整和处理。
你在实际项目中,对于本地缓存有什么独特的使用经验或遇到过什么问题?欢迎在评论区留言,也请为本文点赞和分享!