
在抖音或者视频号上,那些微信对话合成的视频播放量惊人且收益可观,但制作步骤繁琐。今天我们就来解决这个问题,教你一键制作这类视频。

微信对话视频的赚钱吸引力
很多人都刷到过微信对话合成的视频,它的播放量常常非常可观。这种视频有一种特殊的吸引力,能让观众停留观看。有位大V就是靠这类视频赚得盆满钵满。例如他一条视频百万播放量,通过商品推广链接赚取高额佣金。在网络短视频时代,这种收益模式是很多人向往的,所以大家都想抓住这个赚钱的机会。这些视频受喜爱或许是因为它贴近生活,就好像是周围朋友在聊天那样的自然。
常规制作的繁琐之处
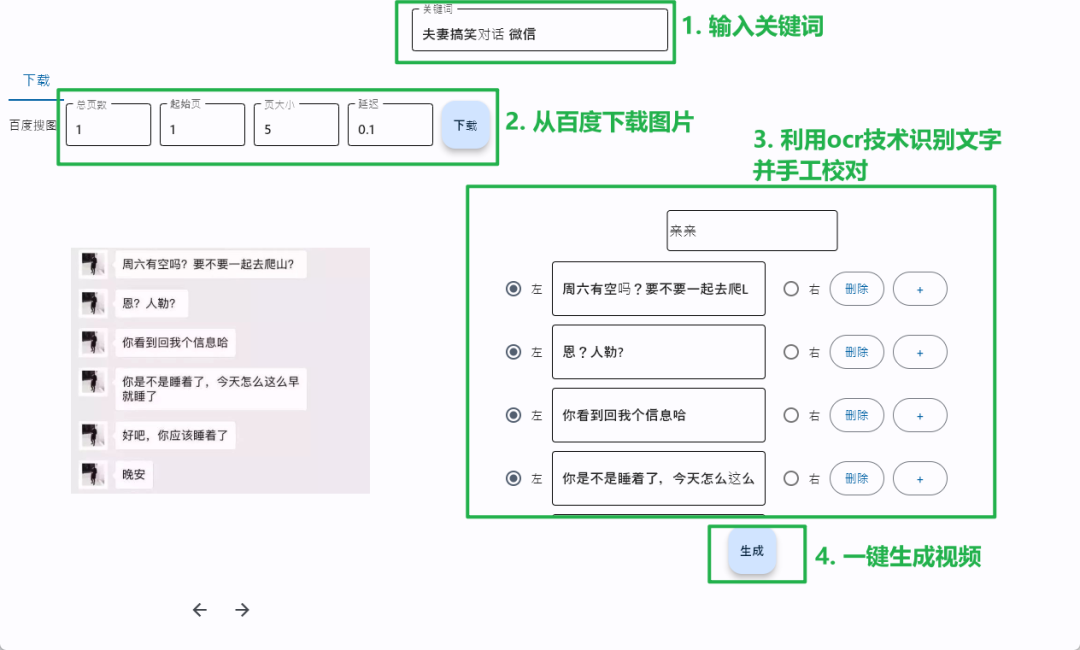
制作这类视频的一般性步骤相当麻烦。首先得去网络找寻对话素材,这个过程耗时长,有时还不尽人意。接着找模拟微信对话的工具,网上工具众多,挑选也需要时间。然后要对生成的图片进行剪辑成视频。这个过程中每一个视频制作几乎都在重复之前的步骤。就比如我认识的一个创作者,每次制作这样一个视频要花费几个小时,很消耗精力,还容易产生烦躁情绪。
一键生成工具的原理
现在我们来了解下一键生成视频的工具原理。它涉及多项技术,爬虫会从百度爬取图片,这能为生成素材提供方便。ocr识别技术用于识别图片文字,像cnocr库不需要网络就能本地识别,能提升效率。模拟微信对话工具则是核心部分。还有server服务、playwright自动化操作以及桌面gui。这一整套下来,利用这些技术组合就可以轻松制作视频,不用再像以前那样繁琐。
具体制作步骤
url = (
"https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj"
"&ct=201326592&is=&fp=result&queryWord=%s&cl=2&lm=-1&ie=utf-8&oe=utf-8"
"&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%s&s=&se=&tab=&width=&height=&face=0"
"&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=%s&rn=%d&gsm=1e&1594447993172="
% (search, search, str(pn), self.__per_page)
)
# 设置header防403
try:
time.sleep(self.time_sleep)
req = urllib.request.Request(url=url, headers=self.headers)
page = urllib.request.urlopen(req)
self.headers["Cookie"] = self.handle_baidu_cookie(
self.headers["Cookie"], page.info().get_all("Set-Cookie")
)
rsp = page.read()
page.close()
except UnicodeDecodeError as e:
self.logger.error(e)
self.logger.error("-----UnicodeDecodeErrorurl:", url)
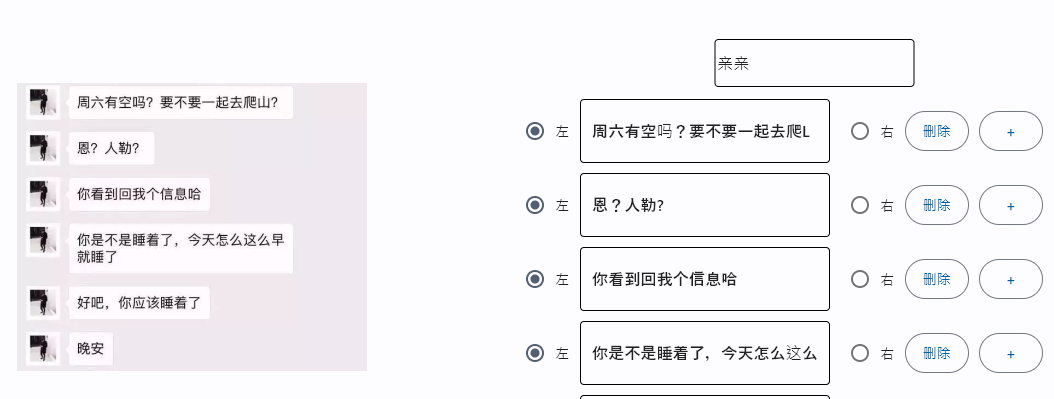
从百度图片批量下载数据是第一步,按关键字搜索图片并提取地址下载。然后用ocr识别图片中的文字。之后分析文字的位置来区分左右对话,不过由于ocr精度问题不能百分百判断准确,所以需要手工修正。基于flet库实现ui界面。紧接着启动模拟微信对话服务,例如用fastapi服务。最后进行自动化操作并截图,将截图和音频合成视频,用到moviepy和Pillow库。
self.model = CnOcr(
det_model_name="ch_PP-OCRv3_det",
)
out = self.model.ocr(
cv2.imdecode(self.read_file(f), -1),
)
for i in out:
i["score"] = float(i["score"])
i["position"] = i["position"].astype(float).tolist()
target_path.joinpath(file_name + ".json").write_text(
json.dumps(out, ensure_ascii=False, indent=4)
)
制作工具的测试结果

我亲自做了测试。在抖音发布了两个这样的视频,第一个视频播放量只有167,但是第二个视频就冲到了1.6万。这说明这个制作工具和方法是可行的。虽然第一个视频播放不高,但应该有诸多因素影响,像发布时间可能受众活跃度不高之类的。而第二个视频就证明这样的视频内容还是很有市场潜力的,只要持续优化视频内容和发布时间等,就会有不错的前景。
res = []
"""去掉标题栏"""
if json_content and "中国" in json_content[0]["text"]:
# 中国联通行,去掉
x = json_content[0]["position"][0][0]
for i in range(1, len(json_content)):
if abs(json_content[i]["position"][0][0] - x) <= 20:
continue
else:
break
json_content = json_content[:i]
"""去掉‘微信’"""
if (
json_content
and "微信" in json_content[0]["text"]
and len(json_content[0]["text"]) < 8
):
json_content = json_content[1:]
"""首行是否为标题"""
if not json_content:
return res
left_top_position = json_content[0]["position"][0]
left_top_position_x = left_top_position[0]
left_top_position_y = left_top_position[1]
if left_top_position_y < 30 and len(json_content[0]["text"]) < 5:
# 认为是标题
res.append({"position": "title", "text": json_content[0]["text"]})
json_content = json_content[1:]
"""同一句话判断的阈值"""
same_sentence_threshold = 30
for i in range(1, len(json_content)):
same_sentence_threshold = min(
same_sentence_threshold,
abs(
json_content[i]["position"][0][1]
- json_content[i - 1]["position"][0][1]
),
)
same_sentence_threshold = max(50, same_sentence_threshold + 35) # 误差
if not json_content:
return res
"""找到左侧和右侧的位置"""
left_around_position = min([i["position"][0][0] for i in json_content])
right_around_position = max([i["position"][1][0] for i in json_content])
"""判断左右"""
n = len(json_content)
text = ""
position_left = 0
position_right = 0
for i in range(n):
if re.compile(r"[0-9]{1,2}:[ ]{0,1}[0-9]{1,2}").findall(
json_content[i]["text"]
):
# 微信时间
continue
if "微信" in json_content[i]["text"]:
# ”微信“标题
continue
if (
i > 0
and abs(
json_content[i]["position"][0][1]
- json_content[i - 1]["position"][0][1]
)
< same_sentence_threshold
):
# 认为当前话跟上一句话是同一句话
text += json_content[i]["text"]
else:
# 现在是另一个人说话,将上一个说的话保存
if text:
if res and res[-1]["position"] == "left":
# 如果上一句话是左边说的,我们更倾向于下一句话是右边的人说的
float_value = 25
else:
# 否则,更倾向于左边的人说的
float_value = -5
if not res:
# 第一句话更倾向于右边的人说的
float_value = 25
if abs(position_left - left_around_position) + float_value < abs(
position_right - right_around_position
):
# 离左侧更近
res.append({"position": "left", "text": text})
else:
# 离右侧更近
res.append({"position": "right", "text": text})
text = json_content[i]["text"]
position_left = json_content[i]["position"][0][0]
position_right = json_content[i]["position"][1][0]
if text:
if res and res[-1]["position"] == "left":
# 如果上一句话是左边说的,我们更倾向于下一句话是右边的人说的
float_value = 25
else:
# 否则,更倾向于左边的人说的
float_value = -5
if not res:
# 第一句话更倾向于右边的人说的
float_value = 25
if abs(position_left - left_around_position) + float_value < abs(
position_right - right_around_position
):
# 离左侧更近
res.append({"position": "left", "text": text})
else:
# 离右侧更近
res.append({"position": "right", "text": text})
if len(res) == 1:
return []
return res
获取工具的方式
如果有需要这个工具的小伙伴,可以在公众号回复“微信对话生成”就可以获取全部源代码。这是非常方便快捷的获取方式。只要按照上面的步骤操作,大家都可以轻松制作出微信对话合成视频,迈出赚钱的第一步。
你是否也想尝试制作这样的视频来获取收益了?希望你留言分享你的想法。
app = FastAPI()
app.mount(
"/static",
StaticFiles(directory=MAIN_PATH.joinpath("weixin_chat", "static")),
name="static",
)
@app.route("/")
def index(*args, **kwargs):
return HTMLResponse(
MAIN_PATH.joinpath(
"weixin_chat",
"index.html",
).read_text(encoding="utf-8")
)







