
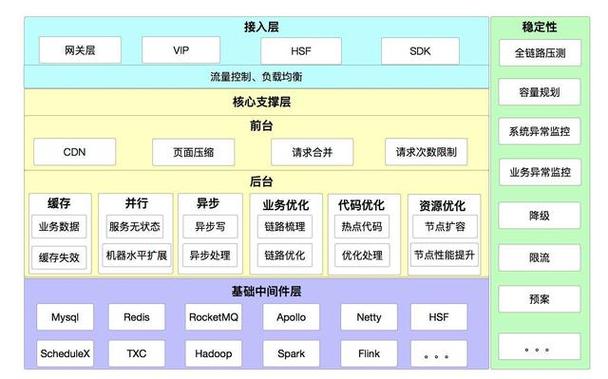
在Feed系统中,计数缓存的处理是一个复杂且关键的问题,其不仅涉及数据类型的缓存,还关乎不同业务场景下的成本与性能。像微博的EXISTENCE缓存层解决存在性判断业务,COUNTER缓存应对计算器场景。而传统计数缓存方案存在诸多问题,值得深入探讨。
传统计数缓存的成本问题
传统的Redis、Memcached计数缓存方案,成本相当高。就拿每日新增的十亿级的计数来说,就需要新占用百G级的内存。这种巨大的成本开销,对于企业来说是个不小的负担。例如在一些大型互联网公司,数据量庞大,如果都采用这样的传统方案,光是内存方面的投入就是一笔巨额资金。而且还有计算成本、运维成本等其他方面的耗费。
在业务越来越复杂,数据量不断增加的情况下,这种传统方案的成本会逐步攀升。它没有考虑到在超大数据量情况下如何进行优化,导致在面对大规模计数缓存需求时显得捉襟见肘。
计数业务的经典构建模型
先来看看db + cache模式。这种模式在早期比较通用成熟。在微博的应用就可以看到,上线初期采用了它。不过随着业务发展,在一致性要求较高的计数服务中,以及海量数据和高并发访问场景下,它的弊端开始暴露。例如在一些特定时段,数据的准确性难以保证,并且运维成本和硬件成本较高。
另一种基于Redis的计数接口INCR、DECR构建的计数缓存模型。通过利用Redis的功能,加上hash分表,master - slave部署方式,可以实现中小规模的计数服务。但当数据量上升到千亿级的历史海量计数以及每天十亿级的新增计数时,这种直接使用Redis的计数模型就会出现严重的成本和性能问题。
Redis应用中的实际成本计算
如果是1000亿计数,使用Redis的话,从内存角度来看,仅内存就需要100G * 65 = 6.5T以上的空间。再考虑到一个master配3个slave的部署方式,总共需要26T以上的内存。按照单机内存96G计算,还要扣掉Redis其他内存管理开销、系统占用等,这样计算下来需要300 - 400台机器。这么多的资源消耗无论是从硬件采购、电力消耗还是机房空间等方面都是巨大的投入。
大量机器的存在也会增加运维的复杂性。每台机器都可能出现故障等问题,给维护带来很大的压力,一旦出现问题也会影响数据的准确性和业务的正常运行。
Feed系统中的特殊计数处理
在Feed系统的计数场景中,有其特殊之处。例如单条feed的各种计数都有相同的key(微博id)。如果合理利用这个特性,把这些计数存储在一起,就能节省大量的key的存储空间,能将1000亿计数变成330亿条记录。这是一个相当可观的优化。
同时进一步对CounterService增加SSD扩展支持,采用按table滚动的方式,使得老数据落在ssd,新数据、热数据在内存。例如,1.28T的容量几乎可以用单台机器来承载。当然为了保证访问性能、可用性等,还是需要采用hash到多个缓存节点,并添加主从结构的方式。
内存优化策略
在提高性能和降低成本方面,内存优化是关键。其中一种方式是通过预先分配的内存数组Table存储计数,并且采用double hash解决冲突。这种方式就避免了Redis实现中的大量指针开销。这样可以让内存的利用更加高效,减少不必要的内存浪费。
而在数据结构设计上,采用Schema支持多列也很有效。一个feed id对应的多个计数可以作为一条计数记录,还能支持动态增减计数列,并且每列的计数内存使用精简到bit,通过这样的方式,大大降低了内存的占用。
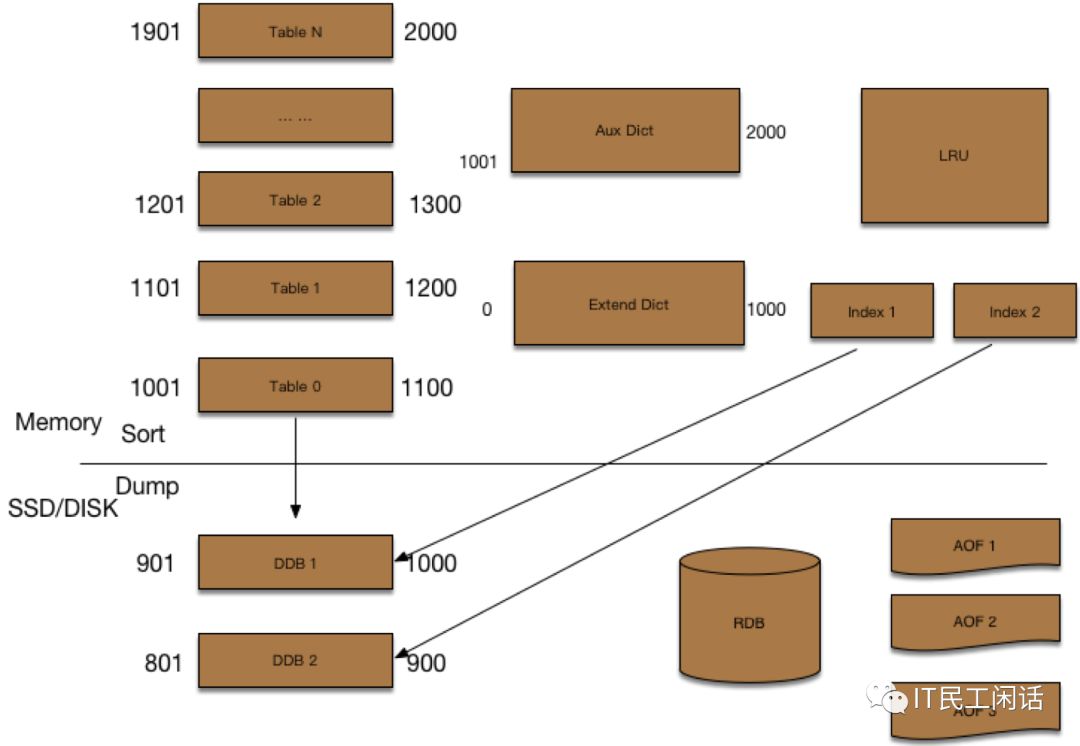
优化后的性能提升
经过上述优化之后,效果显著。内存占用降为之前的5 - 10%以下,这在成本上有了大大的降低。而且从读取性能来看,一条feed的评论/赞等多个计数、一个用户的粉丝/关注/微博等多个计数都可以一次性获取,读取性能大幅提升。
这些优化措施基本彻底解决了计数业务的成本及性能问题。让Feed系统在面对计数缓存时,既有较好的性能表现,又不会因为成本过高而难以承受。现在,你认为在其他类似的大数据缓存场景中,哪些策略也是可以通用的?欢迎点赞、分享并在评论区留下你的观点。




