在数据驱动业务的当今,小红书数以亿计的日数据量给数据分析带来挑战,而TiDB数据库凭借独特特性成为有力解决方案。下面,一起来看看TiDB是如何在小红书的数据海洋中“大显身手”的。
数据使用多样性
小红书每天数据流量大,对数据使用的方式也多元。有时需数据库做TP短查询及高频写入,有时要做聚合分析。TiDB的HTAP架构完美适配,它能灵活切换不同数据使用模式,让企业在处理小红书海量数据时,无论是进行快速数据存取,还是深度数据洞察,都能游刃有余。其强大的数据支撑能力,让企业在小红书的业务运营中抢占先机。
传统数据库面对数据使用多样性时往往捉襟见肘,TiDB却表现出色。它可以依据企业不同需求,在多种数据处理模式间平滑过渡。在小红书业务场景中,这种灵活性极为重要,能帮助企业更精准地分析用户行为、市场趋势等,挖掘数据背后的巨大商业价值。
更高的时效性
不少数据分析引擎虽计算速度快,但实时分析能力弱,而TiDB在这方面表现优异,提供了更高的时效性。对于小红书上海量不断更新的数据,TiDB能及时捕捉并处理其变化,确保企业获取到的信息是最新的。这对于企业迅速调整营销策略、应对市场变化十分关键。
比如在小红书热门话题营销中,TiDB能实时分析话题热度、用户参与度等数据。企业依据实时数据调整投放策略,可更有效地触达目标用户,提升营销效果。高时效性让TiDB成为企业在小红书数据世界里快速决策的有力武器。
业务逻辑分层优势
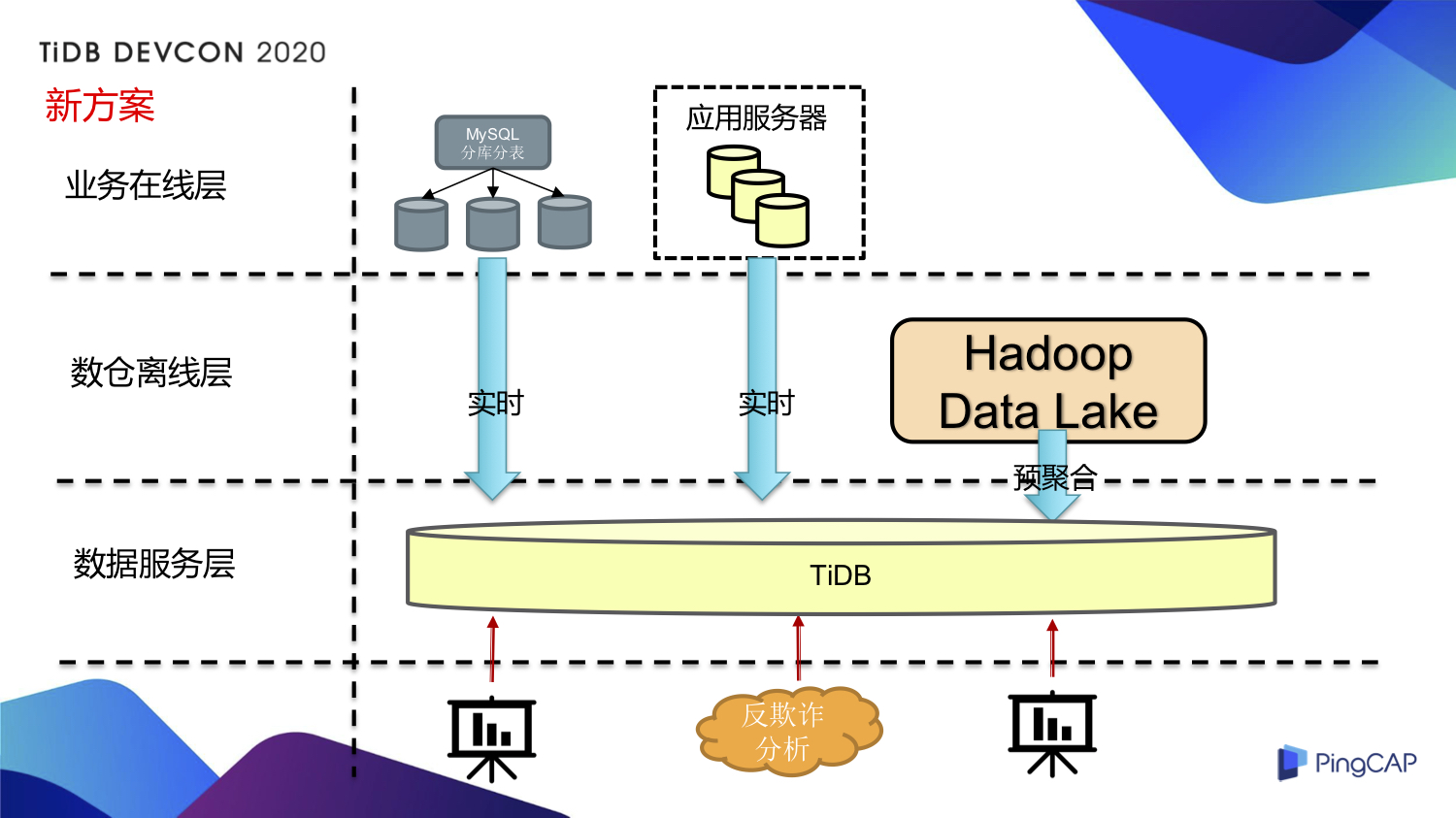
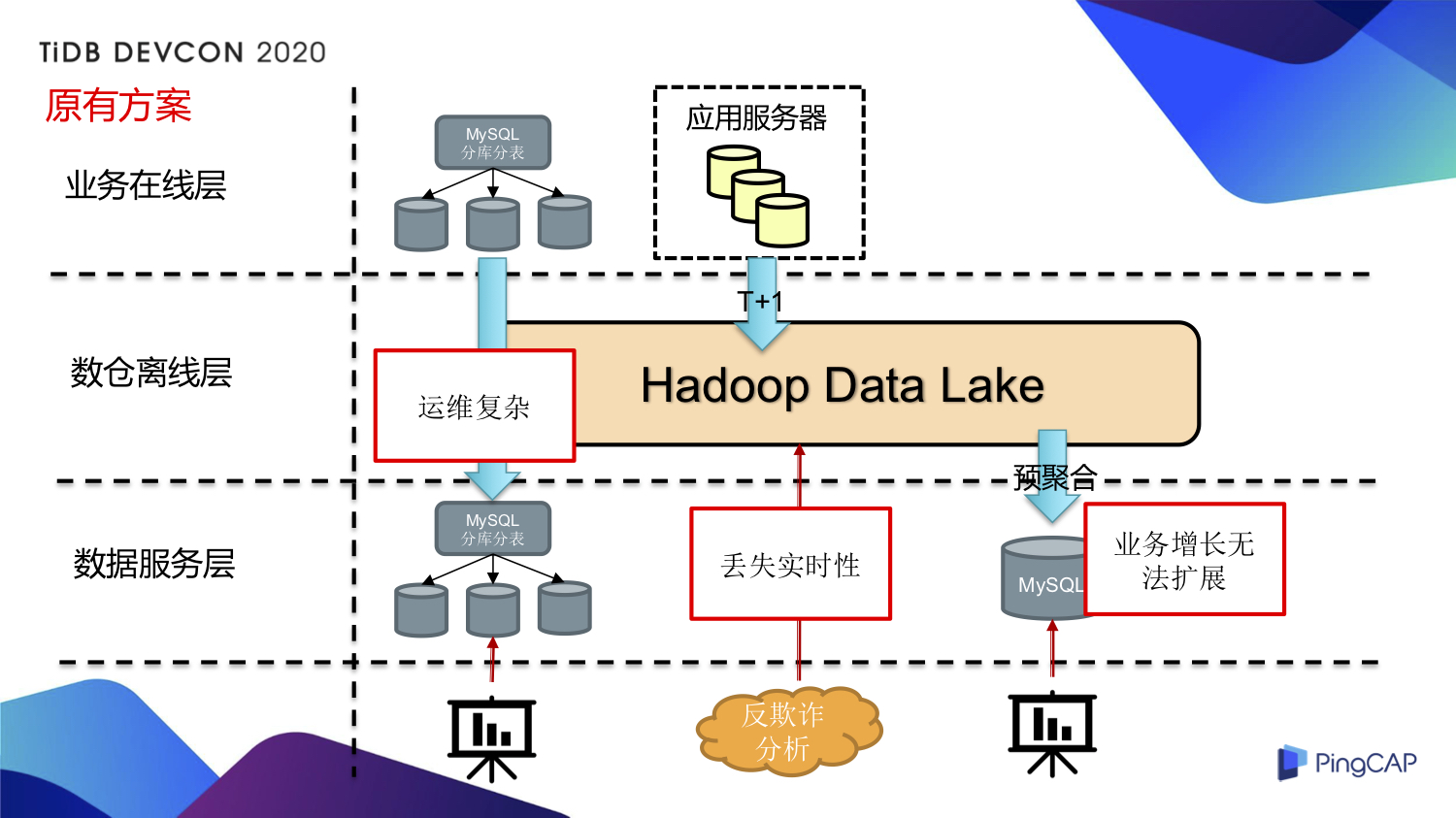
从业务逻辑上看,小红书业务分为业务在线层、数仓离线层和数据服务层。TiDB在不同层次都能发挥作用,为企业整体业务逻辑提供坚实支持。在业务在线层,它能保障数据快速读写,满足用户实时操作需求;在数仓离线层,可对数据进行长期存储和深度分析;在数据服务层,则能高效输出分析结果,服务企业决策。
这种分层支持让企业在小红书的业务运营更加有序。以电商企业为例,在业务在线层处理订单交易数据,数仓离线层分析用户购买习惯,数据服务层为营销策略制定提供数据支持。各层相互协作,TiDB充当了关键的纽带角色。
在线MySQL分库分表场景适配
在在线的MySQL分库分表场景中,对小红书的数据查询不能影响线上库,通常只能查询从库,TiDB能很好适配这种场景。它可作为MySQL的大从库,在不影响线上主库的前提下进行数据查询、事务处理、JOIN和聚合等操作。即使原来有一万个分表,TiDB集群也能存下,无需繁琐分表。
使用TiDB后,企业无需担心分库分表带来的管理难题。比如原来在MySQL上分表多,查询效率低、维护成本高,现在TiDB将其整合为一张大表,方便快捷。同时,数据自动同步和查询路由功能,让运维人员轻松应对海量数据管理。
扩容便利性

扩容对于数据库是家常便饭的事,但TiDB在这方面优势明显。遇到数据量增大情况,它能直接添加节点,数据自动重新均衡,操作简单方便。在小红书数据量呈爆炸式增长情形下,这种便捷的扩容方式可让企业快速应对数据存储和处理需求的增加,无需担心数据分布不均导致的性能问题。
例如,当小红书开展大型促销活动,数据量瞬时上升,TiDB能迅速扩容,确保系统稳定运行。而且无需像传统数据库那样进行复杂的数据迁移和手动调整,为企业节省大量时间和人力成本。

TiDB的不足之处与对比
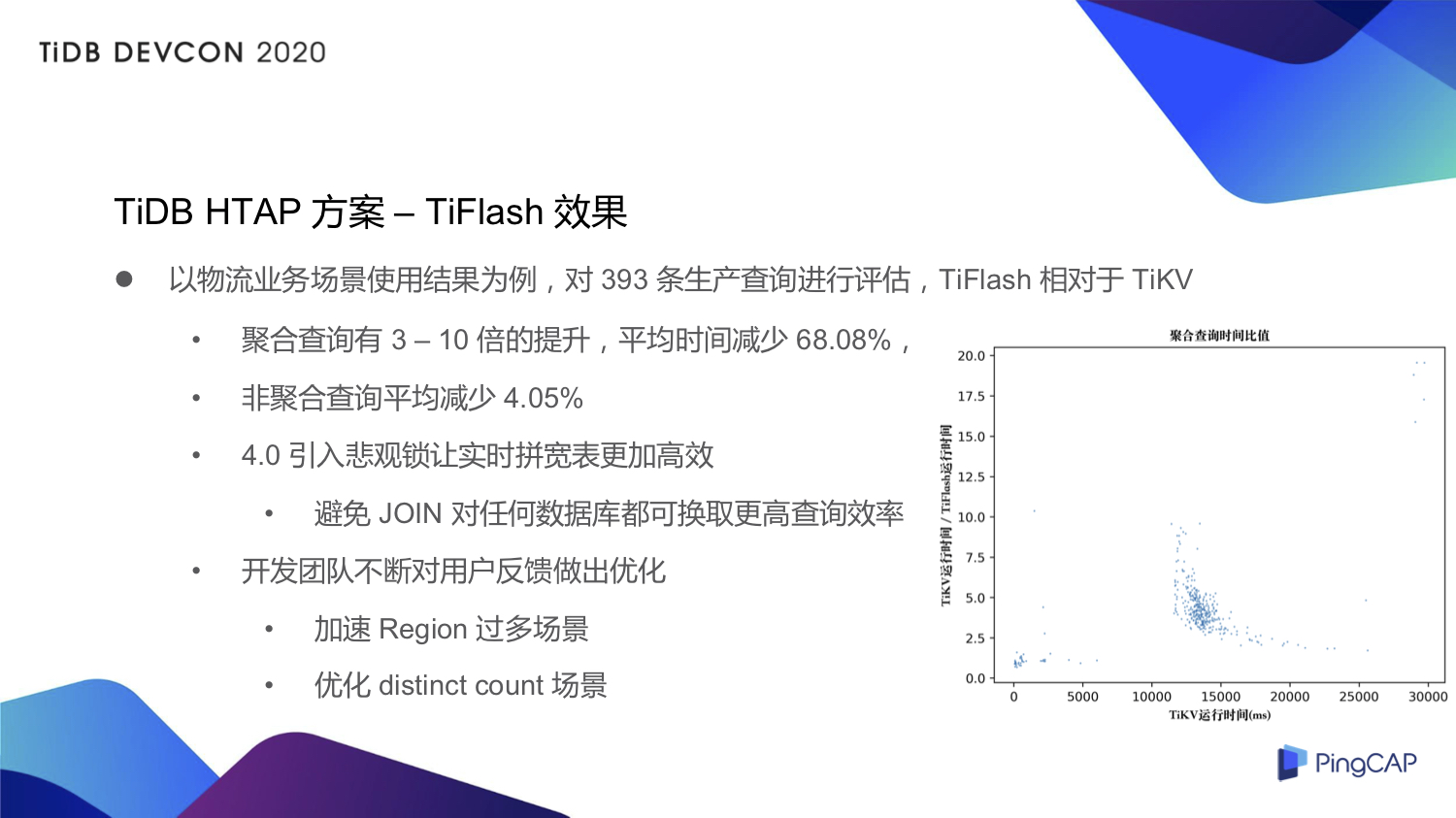
TiDB 3.0在OLAP分析能力上稍显不足,TiKV基于行存,和专门分析的列存引擎相比有差距。不过TiDB通过Raft Learner复制机制,将数据低延迟同步到TiFlash中进行弥补。与ClickHouse列存引擎相比,ClickHouse计算性能比TiFlash快一点,但TiDB有其他优势,如运维成本低等。
在实际应用中,企业可根据自身需求进行选择。那你认为在小红书这样的数据场景中,TiDB和ClickHouse谁更具优势?如果觉得文章有用,欢迎点赞并分享给身边需要的人!