
在当今数字化时代,数据是企业决策的核心依据。小红书2017年后业务和用户的爆发式增长,催生了大量数据分析需求,这无疑是一个值得深入探究的亮点。
业务增长与数据需求爆发
2017年后小红书的业务迅速拓展,吸引了庞大的用户群体。这种快速的增长使得原有的数据分析和系统数据供应模式难以满足需求。不同的业务板块都开始急切寻求更为深入的数据洞察,例如商业智能分析对于企业战略规划的重要性愈发凸显。运营团队急需从大量数据中了解用户行为,从而调整运营策略,这些需求的产生促使小红书大数据团队寻求更强大的技术支持。
随着业务向多元化发展,数据需求的种类也变得复杂多样。各地的业务部门,无论是负责营销推广的团队,还是产品研发团队,都需要依据详细的数据来开展工作。数据不再仅仅是数字的堆砌,而是成为了引导企业前行的指南针。
多种OLAP分析引擎的引入
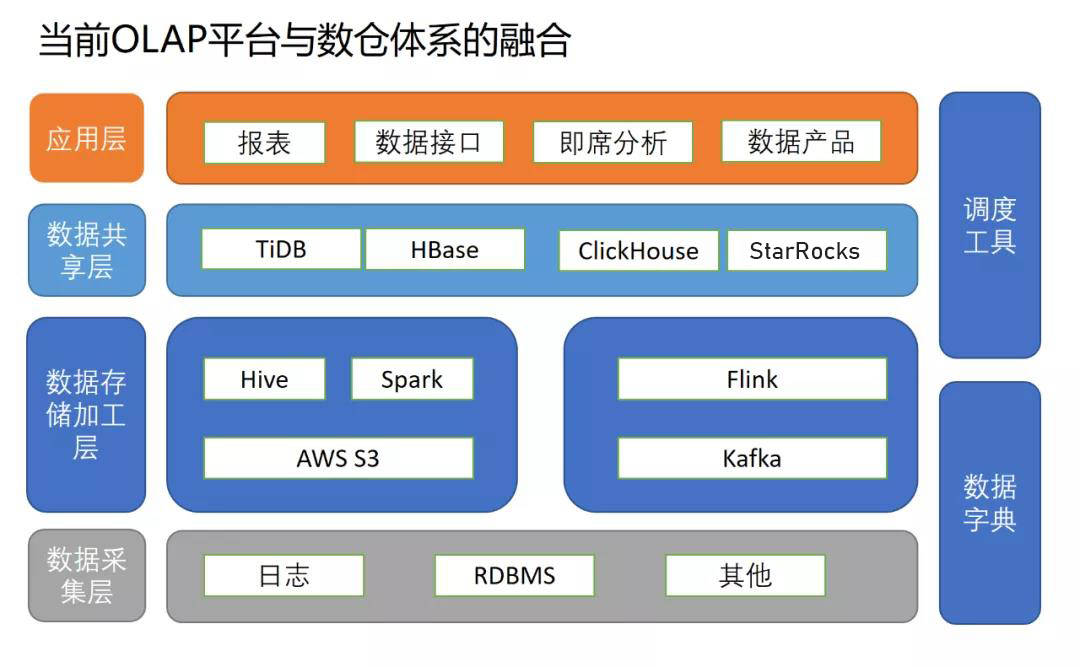
为了应对复杂的数据需求局面,小红书大数据团队开始引入多种OLAP分析引擎。这些引擎像是为小红书大数据的处理注入了新的活力。StarRocks被引入后,为构建全新的统一数据服务平台奠定了基础。这一平台极大地改变了既有数据链路开发状况。在以往,数据链路开发复杂,涉及众多步骤和不同工具间的协调,如今开发复杂性大大降低。
同样,ClickHouse的引入是为了打造性能强劲的数据分析平台。在当今快节奏的商业环境中,数据的实时性需求日渐增加,无论是对用户行为的实时分析还是快速响应市场趋势。通过ClickHouse建设的平台,能够显著缩短响应时间,这为小红书的实时决策提供了有力保障。
实时数仓的设计与搭建

小红书大数据团队进入到实时数仓的整体设计与搭建阶段。这一阶段涉及到对各业务团队数据接口的统一规划。在构建数据服务平台时,充分考虑到了内部和外部不同的应用系统对接需求。以具体项目为例,如果某个业务团队需要紧急获取用户行为数据以便调整线上推广策略,这个统一的数据接口能够及时高效地提供数据。
构建这个实时数仓并非易事,它需要考虑到不同业务场景下数据的流入和流出。在技术层面,要解决数据一致性、完整性等问题,保障数据准确无误地在各个环节流转。这一过程涉及到众多技术人员的参与,他们依据各自的专业知识和经验来打造这个复杂而关键的平台。
离线数据处理的方式
离线数据处理方面,Hive/Spark展现出了其高可扩展的批处理能力。它们承担着离线数仓中ETL操作和数据模型加工等重任。例如在离线数据仓库的构建过程中,每天都有大量原始数据流入,Hive/Spark能够快速对这些数据进行提取、转换和加载。
而在数据共享层,它主要提供对外服务的底层数据存储。这里会面临多种来源的数据写入需求,包括离线和实时的数据。为了满足不同场景下的查询需求,在处理时会将数据写入相关的数据库组件。这个过程需要考虑到多种因素,如存储成本、查询效率等。

数据产品与应用层的构建
在应用侧,利用StarRocks和ClickHouse强大的OLAP查询能力,小红书构建了多个实用的数据产品和平台。报表平台能够为运营和管理团队提供直观的数据展示,数据分析师也能够在平台上进行即席分析。例如在流量分析平台,能够快速得到不同时段、不同地区用户流量的精准数据。

而在应用层,主要面向管理和运营人员以及数据分析师等不同群体,需求形势较为复杂。对于运营人员,报表要满足高并发、低延迟并且能够快速适应需求变化。对于数据分析师而言,需要能够支持复杂sql处理和海量数据查询等要求。
StarRocks在广告业务中的应用

StarRocks在广告业务中的应用体现出独特的优势。基于其本身高效查询的能力和支持高QPS特性,为广告的算法策略、实时计费和平台的实时数据报告提供了一体化服务。在实际操作中,通过将广告主ID作为排序键的前列优化查询,以及支持按照广告主ID进行Hash分桶等操作,显著提高查询效率。
这对于广告业务的影响极大,特别是在高并发场景下。比如在大型促销活动期间,广告的查询需求会瞬间爆发,依靠StarRocks这些特性能够快速定位广告主数据,减少查询数据量。同时,由于StarRocks采用MPP查询架构,底层数据的两级分片方式非常适合广告主业务的查询需求。
你是否觉得企业的数据转型能够影响到你在平台上的使用体验?快来评论分享你的看法,也请点赞和分享本文。








