小红书在数据分析方面做出重大变革,将自助分析场景的主力查询引擎从Presto迁移到StarRocks 3.0,这一举措背后隐藏着许多技术考量与变革因素。
StarRocks的吸引力
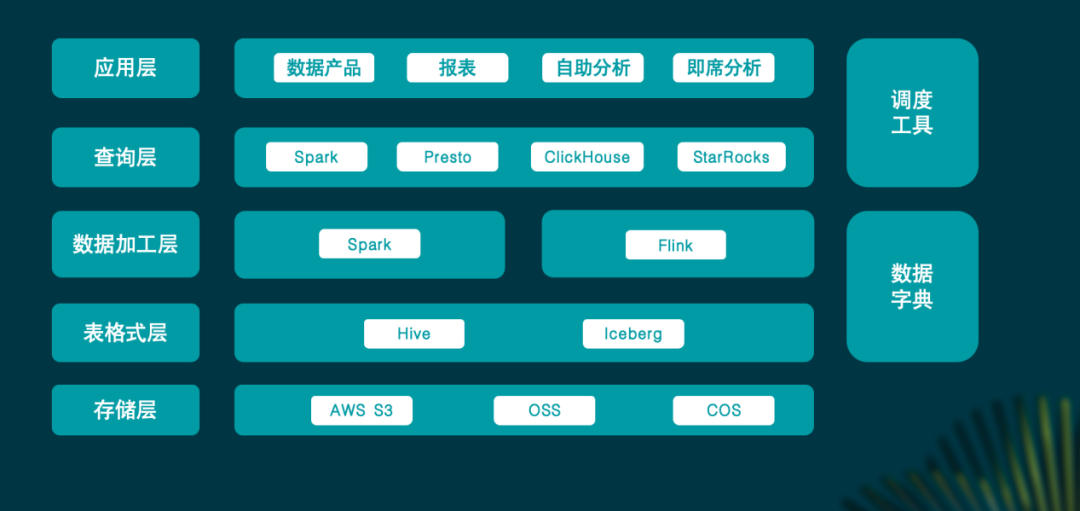
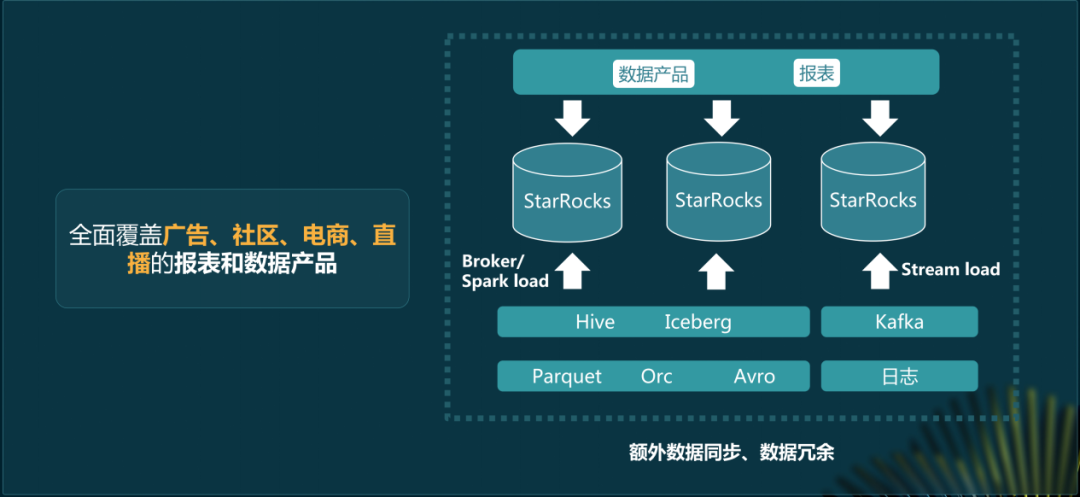
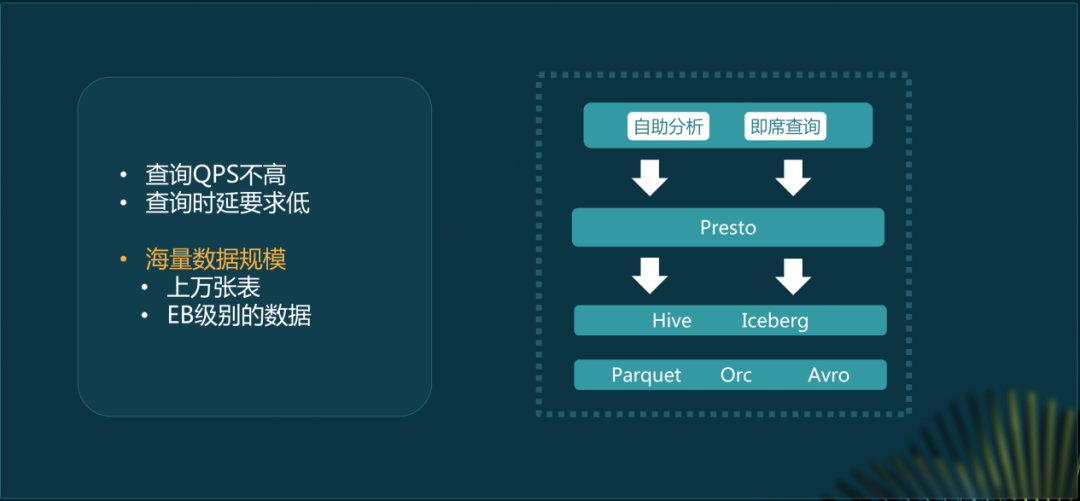
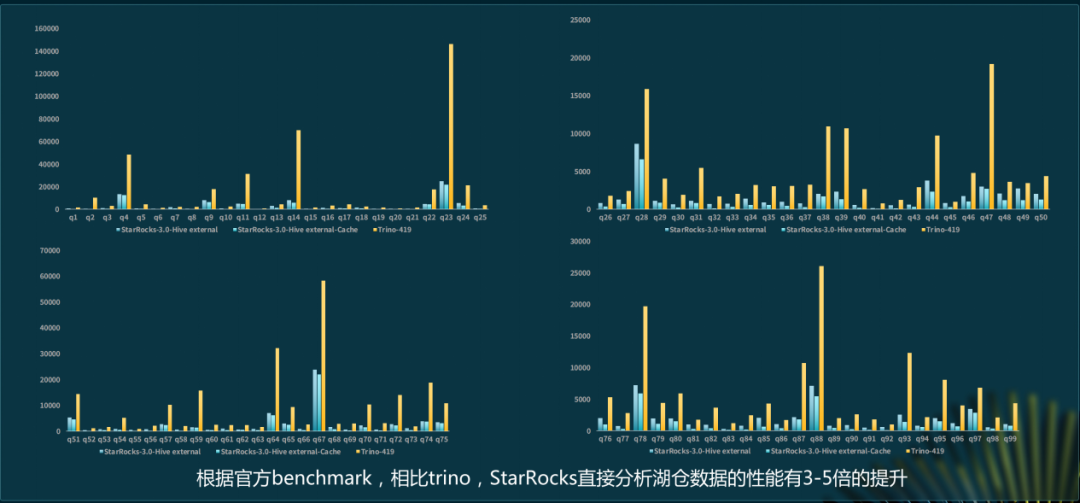
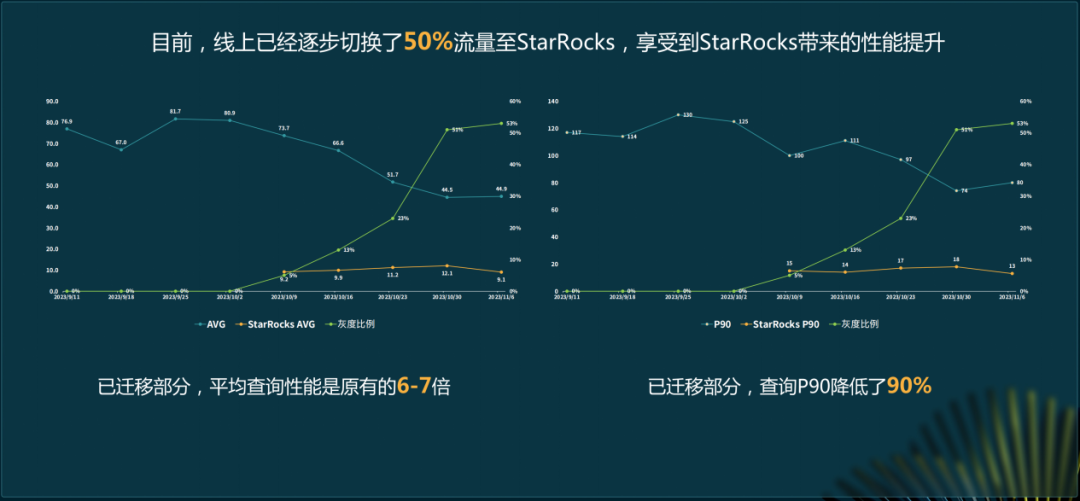
小红书的数据规模极大,包含上万张表、EB级数据。自助分析场景下查询性能很关键。StarRocks 3.0湖上分析能力增强。它使得已迁移部分的平均查询性能提升了6 - 7倍。迁移是因为StarRocks能适应大数据环境下的查询需求。另外它在整体能力上有显著提升才有替换Presto的可能。
而Presto之前也发挥了很大作用。在过去几年中,Presto因其交互式分析和复杂查询优势帮助小红书提升查询性能和用户体验。

迁移的挑战
数据规模如此巨大,不可能将所有数据同步到StarRocks里。这就需要找到一个折中的方案来实现过渡。而且小红书的用户即分析师,他们的使用习惯很难改变。这要求迁移过程要尽量减少对他们使用习惯的影响。
Presto在过去长时间占据主力查询引擎位置,有它的用户群体和使用惯性。迁移需要克服这些既有的习惯和关系的约束。
平滑迁移之路
兼容Trino查询语义对迁移起到很大帮助。这有助于让整个迁移过程更平滑。在用户习惯难以改变的情况下,这样能在很大程度上保留之前的使用感受。
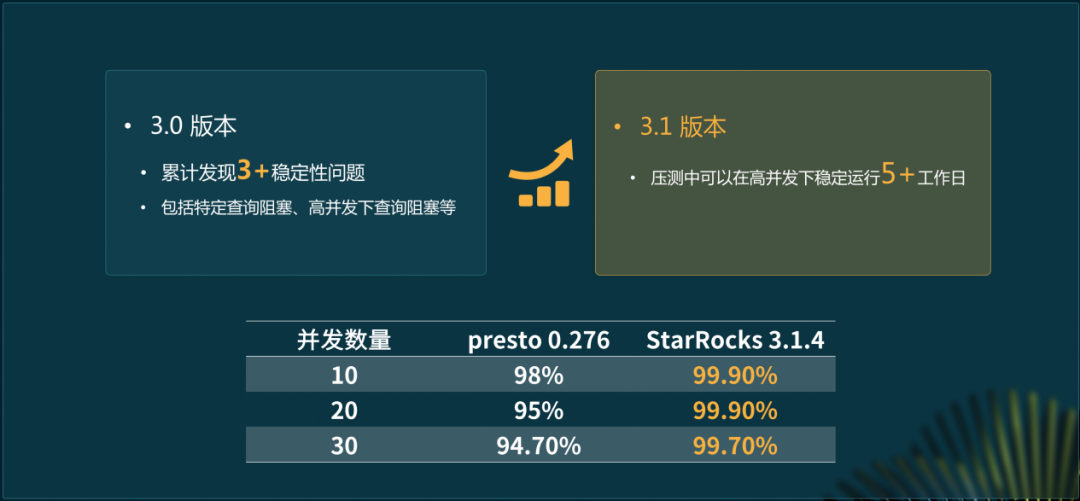
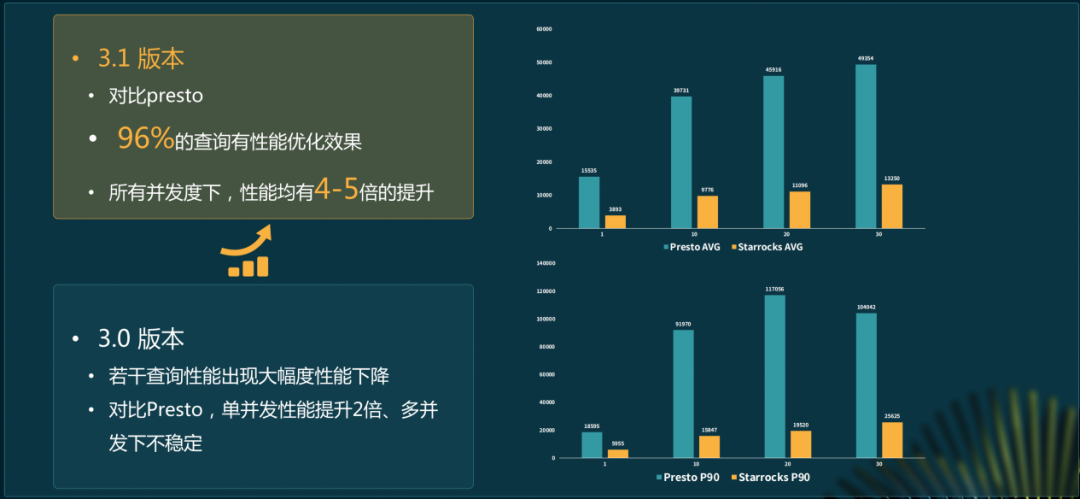
而在迁移过程中用到了灰度迁移机制。这一机制使得迁移过程不是一蹴而就,能逐步实现从Presto到StarRocks的转换,避免出现突发大规模问题。
现存版本的优势
目前小红书线上稳定版本已经升级到3.2。该版本有不少新的优势功能。它提供了CTAS语法的支持,这大大拓展了查询功能。
还通过JNI接口扩展更多的table format。并且有很多Iceberg相关的兼容性优化。这些优化有助于进一步提升整个数据平台的性能和适应性。

路由与定制开发
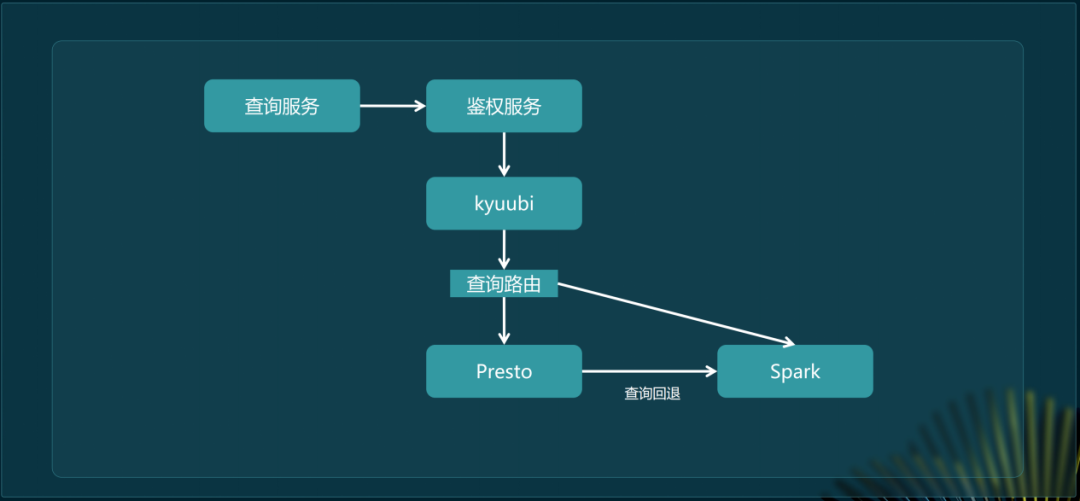

在Kyuubi上做了深度定制化开发。其中查询的路由功能和灰度功能是核心。在以Presto为主的查询场景下,如需处理特殊语法或大数据量扫描,就会将查询路由到Spark执行。
这样能利用不同引擎的优势,提高查询效率。使不同类型的查询在合适的引擎上进行处理,充分发挥各引擎特点。
架构优化探索
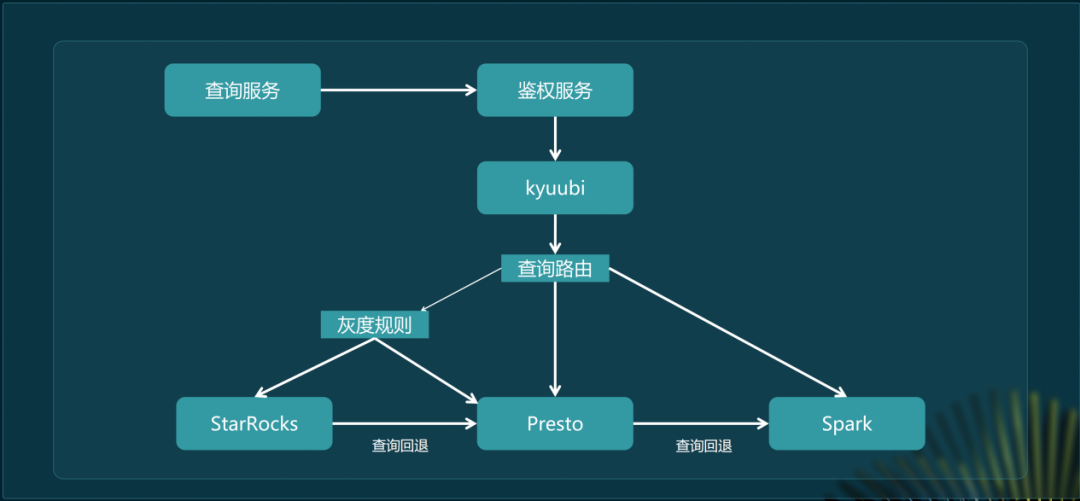
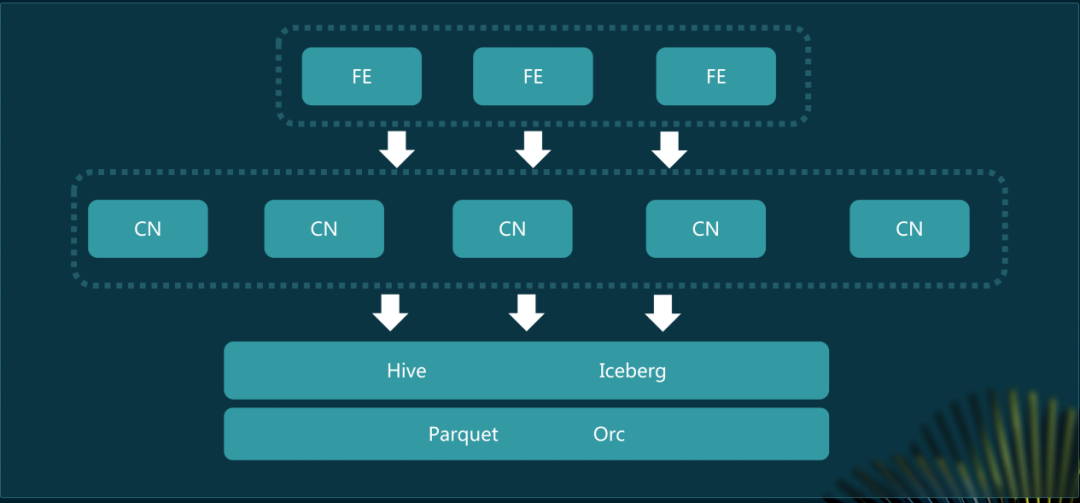
StarRocks湖上分析集群分FE、CN两部分,CN作为无状态计算节点符合弹性伸缩理念。架构上FE和少量CN采用包年包月方式保证基础服务,90%的CN节点用Spot申请,可在低峰期归还机器。
目前未开启缓存,还要探索本地缓存和分布式缓存进一步优化查询性能。存算分离模式能降低技术栈复杂度,湖仓一体架构融合存算分离和湖上分析将提升数据开发和分析能力。
最后想问大家,你认为在大数据处理的引擎迁移中,最重要的考量因素是什么?