
在当今数据驱动的环境里,数据的准确性无比重要,就像小红书这样业务繁忙的数据交互场景,数据一致性校验的成功落地简直就是业务的生命线。一旦数据在传输中出错,那带来的损失不可想象,这就是此事的痛点。
小红书的数据传输现状

在小红书内部,数据传输服务每天都在忙碌。众多业务依靠它,大量的数据同步任务靠它保障。这里面,源端和目标端的数据一致性必须严格保证起来。例如在日常的数据同步,像从一个地区的用户数据从源端传输到目标端存储,一旦出错肯定会干扰到具体的业务运作。这就是现实面临的压力,必须要有扎实的数据一致校验才行。而且小红书的业务场景复杂,目前业界的一些解决方案搞不定。
这种情况很让人担心。像公司在业务扩张阶段,如果数据不一致,业务发展方向可能都会出错。这需要专门针对小红书的校验工具来保证数据传输过程的数据质量。
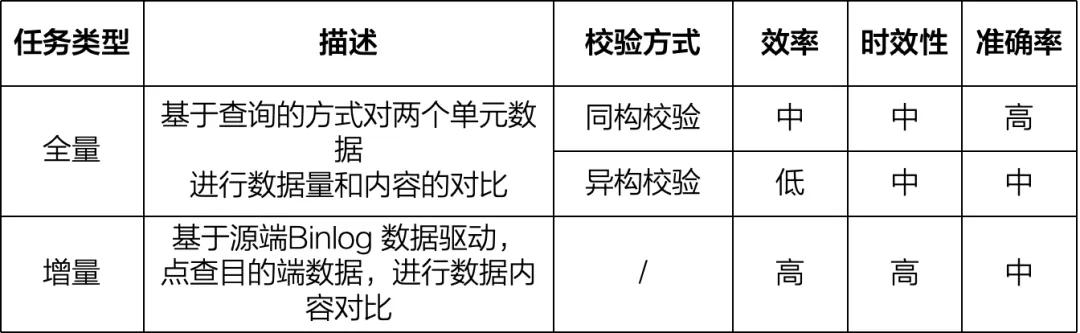
全量数据校验的分类
在实际操作全量数据校验时,会根据源端和目标端校验表结构的差异有同构校验和异构校验之分。就好比一个是双胞胎对比(同构校验),一个是跨种族对比(异构校验)。
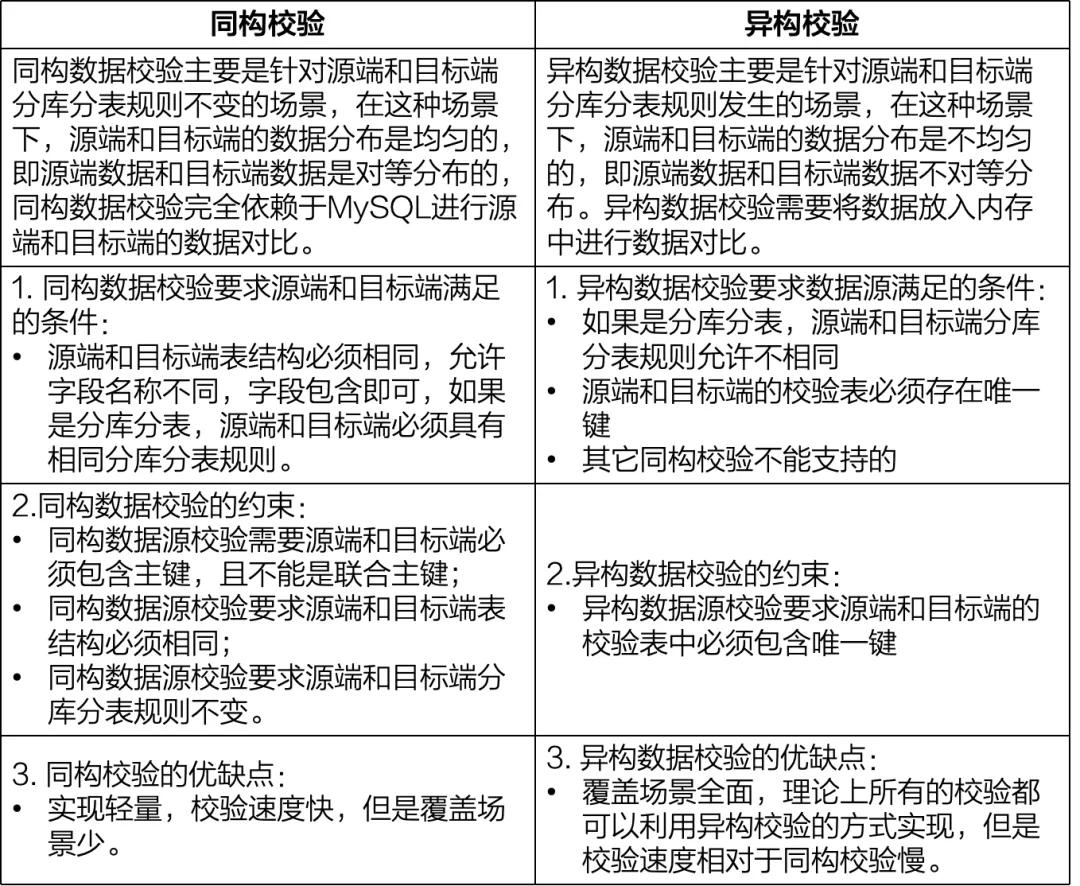
全量数据校验是对全部数据的一次性对比。实际操作中,这个校验会多次进行。比如说一天可能会运行三次以保证数据准确无误。校验的时候,工具会自己选择校验方式,用户都不用操心。根据数据源类型、数据分布、任务配置这些来确定校验方式。
全量数据校验的执行过程
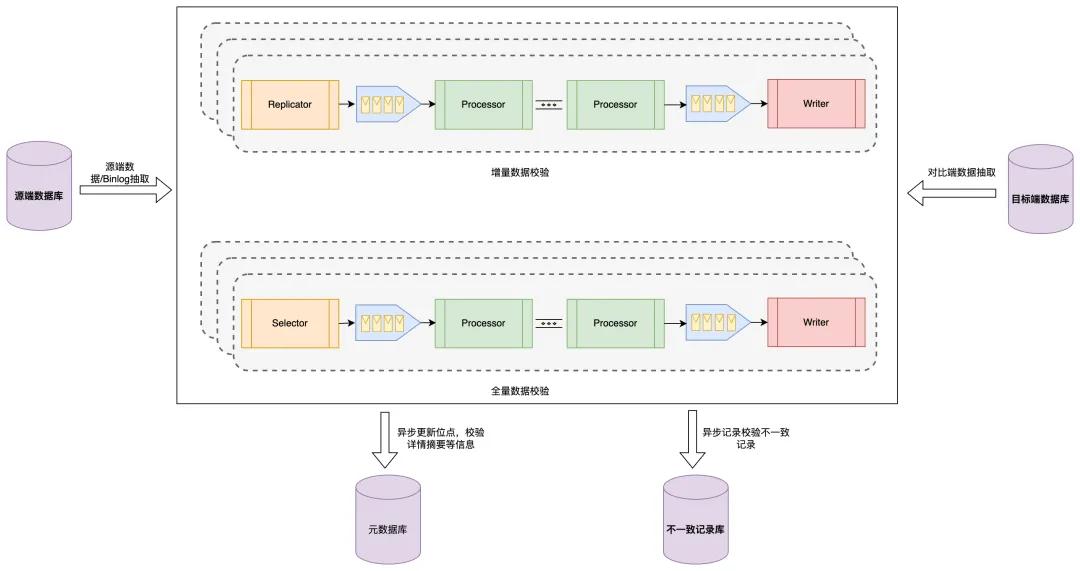
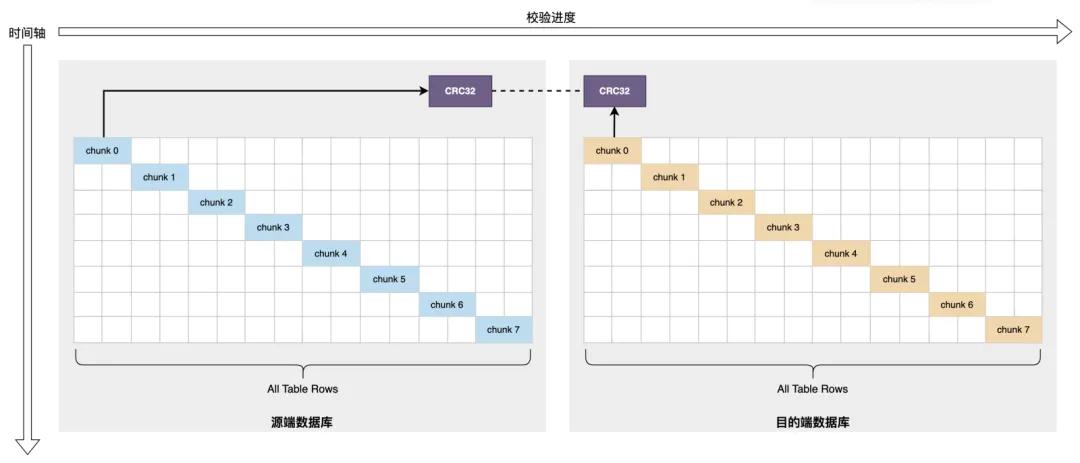
全量数据校验时是分批提取数据块的,从源端和目标端。比如从10万行数据里每次取1000行这种。然后对比数据块验证一致性。这里可以配置数据块大小,具体的分块策略是可控的。
当进行特定时刻的校验时,采用Hash校验和(像CRC32)来判断数据是否一致。在校验同构数据时,校验块大小要小心设置,大了数据库压力大,还容易区间数据不一致。
增量数据校验的重要性
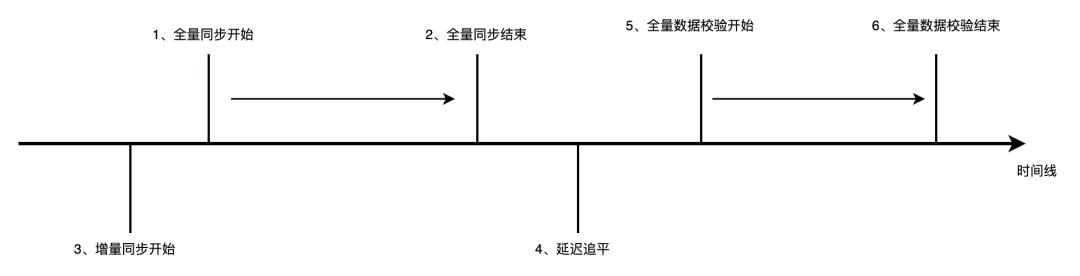
增量数据校验着眼于新的数据变化。在数据迁移、更新过程中非常关键。打个比方,就像新上架的商品数据,从源头要完整准确同步。这对数据一致性和可靠性是不可或缺的。
实际中,这个校验功能是实时监控源端数据变 化并且与目标端对比的。通过主键等找到目标数据库的相应行进行对比。

增量数据校验中的特殊机制
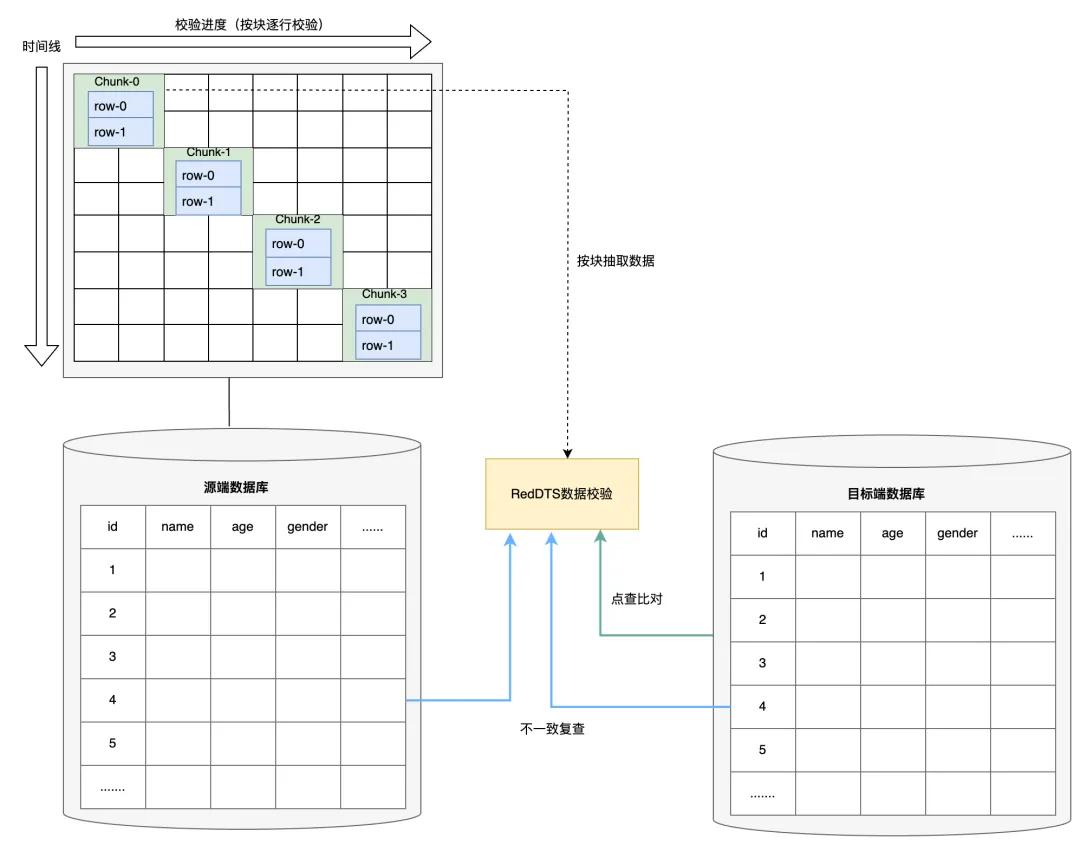
由于可能有延迟和数据频繁变更等情况,源端和目标端数据可能比已知位点新。像网络波动或者大量用户同时修改数据时就会这样。
所以设计了延迟点查和复查机制。比如有一次在大促活动时,数据变更频繁,这个机制就发挥作用,对两边数据库数据进行准确对比。
数据一致性校验在小红书的成果
小红书的MySQL数据一致性校验工具上线后很成功。在数据库迁移、单元化场景发挥大作用。比如说数据库从一个中心转移到几个分中心(单元化)时,数据的准确性得到保障,为小红书内部业务提供了坚实的数据一致保障。
你在工作中有没有遇到过数据不一致带来的问题?希望大家点赞分享,也欢迎在评论区探讨。







